This public forum is happening during Sunshine Week, when we celebrate the public’s right to know and access to information.
That gives us a wonderful opportunity to talk more about how government transparency and disclosure can accelerate artificial intelligence (AI) while protecting privacy, security, and human rights.
As law becomes encoded by technology, code has become law.
Accelerating AI in the public sector must not come at the expense of human rights, civil liberties, or the public’s right to know, which are central to democratic societies.
AI will be part of everyday life, but public sector algorithms have special importance: people don’t have a choice. From making unemployment decisions to getting loans to parole hearings to education and work, code is going to govern how we live, work, play, learn, and govern.
Public sector algorithms must be auditable to ensure that existing inequity and injustice is not codified in a rush to modernize.
Open data and open source code can reveal and check algorithmic bias and racial, gender, or religious discrimination in public services, accommodations, and access to information.
Over the last five years, other nations have enacted laws and regulations that focus on the transparency, participation, and accountability of public sector algorithms, from France to the Netherlands to New Zealand.
In France, the Digital Republic Law mandates transparency of government-used algorithms. Public agencies are required to publicly list any algorithmic tools they use, and to publish their rules.
Imagine Congress ordering federal agencies to do so at Code.gov, and OMB forcing the issue.
Imagine an explicit extension of the Freedom of Information Act to code and meta data.
Imagine investment in the human and technical capacity of the SEC, FEC, & FTC to audit the use of AI across societies.
Imagine every city, state and democratic nation joining a global open algorithms network and committing to engaging everyone governed by code and upholding the rights of the people in these new systems.
Imagine a democratic vision for AI in the public sector that centers on human rights and the needs of the public to know in order to be self-governing, instead of authoritarian coercion, control, secrecy, opacity, and secrecy
This Sunshine Week, please commit to pushing our government of, by, and for the people to collaborate WITH the people in developing legislation and rules that govern its use, codifying our “bill of rights” into the technologies we develop and use every day.
Elon University and Pew Research Center asked experts what the impact of digital disruption will be upon democracy in 2030: Perspectives differ! About half predicted that humans will use technology to weaken democracy over the next decade, with concerns grounded … Continue reading →
When I asked whether when or if it is acceptable for the United States government to charge companies, journalists and the public for government data, citing the example of paywalled immigration data, the chief information officer of the United States told me that “it’s part of the commercial equation” and that it was “actually a discussion point for the strategy” in her office in the White House Office of Management and Budget.
“I don’t have a specific answer,” Suzette Kent went on. “That is something that we’re looking at because there’s many tenets of it. There’s some data the government collects & document on behalf of the american public that may have the mode. There’s other types of data, that people are asking for. It’s a broad spectrum and one we are going to continue to explore.” Kent was speaking at the Data Coalition’s Data Demo Day on June 6 in Washington, DC. Video of the keynote speech she gave on data is embedded below:
When asked about the continued disclosure of data in PDFs and non-machine readable forms by federal agencies, despite President Barack Obama’s 2013 executive order, Kent said simply that she advocates compliance with every executive order and law and cited a Cross-Agency Priority goal to remove paper from agency systems.
Charging for public data is not a new topic or debate, but it has continued to be relevant during the Trump administration, when new concerns have grown about government data access, collection, and quality.
As I wrote back in 2014, local, state and national governments across the United States and around the world can and do charge for access to government data.
While some developers in Europe advocate charging for public sector information (PSI) as a way to ensure higher service levels and quality, adding fees does effectively charge the public for public access and has frequently been used as a barrier to press requests:
A city hall, state house or government agency charging the press or general public to access or download data that they have already paid for with their tax revenues, however, remains problematic.
It may make more sense for policy makers to pursue a course where they always make bulk government data available for free to the general public and look to third parties to stand up and maintain high quality APIs, based upon those datasets, with service level agreements for uptime for high-volume commercial customers.
Instead of exploring a well-trodden path, the United States government should follow the money and determine which data is agencies are currently charging for under public records requests or other means, using FOIA demand to drive open data disclosure.
Video from the event is online at the Wilson Center website. Unfortunately, I found that I didn’t edit my presentation down enough for my allotted time. I made it to slide 84 of 98 in 20 minutes and had to skip the 14 predictions and recommendations section. While many of the themes I describe in those 14 slides came out during the roundtable question and answer period, they’re worth resharing here, in the presentation I’ve embedded below:
As White House special advisor John Podesta noted in January, the PCAST has been conducting a study “to explore in-depth the technological dimensions of the intersection of big data and privacy.” Earlier this week, the Associated Press interviewed Podesta about the results of the review, reporting that the White House had learned of the potential for discrimination through the use of data aggregation and analysis. These are precisely the privacy concerns that stem from data collection that I wrote about earlier this spring. Here’s the PCAST’s list of “things happening today or very soon” that provide examples of technologies that can have benefits but pose privacy risks:
Pioneered more than a decade ago, devices mounted on utility poles are able to sense the radio stations
being listened to by passing drivers, with the results sold to advertisers.26
In 2011, automatic license‐plate readers were in use by three quarters of local police departments
surveyed. Within 5 years, 25% of departments expect to have them installed on all patrol cars, alerting
police when a vehicle associated with an outstanding warrant is in view.27 Meanwhile, civilian uses of
license‐plate readers are emerging, leveraging cloud platforms and promising multiple ways of using the
information collected.28
Experts at the Massachusetts Institute of Technology and the Cambridge Police Department have used a
machine‐learning algorithm to identify which burglaries likely were committed by the same offender,
thus aiding police investigators.29
Differential pricing (offering different prices to different customers for essentially the same goods) has
become familiar in domains such as airline tickets and college costs. Big data may increase the power
and prevalence of this practice and may also decrease even further its transparency.30
reSpace offers machine‐learning algorithms to the gaming industry that may detect
early signs of gambling addiction or other aberrant behavior among online players.31
Retailers like CVS and AutoZone analyze their customers’ shopping patterns to improve the layout of
their stores and stock the products their customers want in a particular location.32 By tracking cell
phones, RetailNext offers bricks‐and‐mortar retailers the chance to recognize returning customers, just
as cookies allow them to be recognized by on‐line merchants.33 Similar WiFi tracking technology could
detect how many people are in a closed room (and in some cases their identities).
The retailer Target inferred that a teenage customer was pregnant and, by mailing her coupons
intended to be useful, unintentionally disclosed this fact to her father.34
The author of an anonymous book, magazine article, or web posting is frequently “outed” by informal
crowd sourcing, fueled by the natural curiosity of many unrelated individuals.35
Social media and public sources of records make it easy for anyone to infer the network of friends and
associates of most people who are active on the web, and many who are not.36
Marist College in Poughkeepsie, New York, uses predictive modeling to identify college students who are
at risk of dropping out, allowing it to target additional support to those in need.37
The Durkheim Project, funded by the U.S. Department of Defense, analyzes social‐media behavior to
detect early signs of suicidal thoughts among veterans.38
LendUp, a California‐based startup, sought to use nontraditional data sources such as social media to
provide credit to underserved individuals. Because of the challenges in ensuring accuracy and fairness,
however, they have been unable to proceed.
The PCAST meeting was open to the public through a teleconference line. I called in and took rough notes on the discussion of the forthcoming report as it progressed. My notes on the comments of professors Susan Graham and Bill Press offer sufficient insight and into the forthcoming report, however, that I thought the public value of publishing them was warranted today, given the ongoing national debate regarding data collection, analysis, privacy and surveillance. The following should not be considered verbatim or an official transcript. The emphases below are mine, as are the words of [brackets]. For that, look for the PCAST to make a recording and transcript available online in the future, at its archive of past meetings.
Susan Graham: Our charge was to look at confluence of big data and privacy, to summarize current tech and the way technology is moving in foreseeable future, including its influence the way we think about privacy.
The first thing that’s very very obvious is that personal data in electronic form is pervasive. Traditional data that was in health and financial [paper] records is now electronic and online. Users provide info about themselves in exchange for various services. They use Web browsers and share their interests. They provide information via social media, Facebook, LinkedIn, Twitter. There is [also] data collected that is invisible, from public cameras, microphones, and sensors.
What is unusual about this environment and big data is the ability to do analysis in huge corpuses of that data. We can learn things from the data that allow us to provide a lot of societal benefits. There is an enormous amount of patient data, data about about disease, and data about genetics. By putting it together, we can learn about treatment. With enough data, we can look at rare diseases, and learn what has been effective. We could not have done this otherwise.
We can analyze more online information about education and learning, not only MOOCs but lots of learning environments. [Analysis] can tell teachers how to present material effectively, to do comparisons about whether one presentation of information works better than another, or analyze how well assessments work with learning styles.
Certain visual information is comprehensible, certain verbal information is hard to understand. Understanding different learning styles [can enable] develop customized teaching.
The reason this all works is the profound nature of analysis. This is the idea of data fusion, where you take multiple sources of information, combine them, which provides much richer picture of some phenomenon. If you look at patterns of human movements on public transport, or pollution measures, or weather, maybe we can predict dynamics caused by human context.
We can use statistics to do statistics-based pattern recognition on large amounts of data. One of the things that we understand about this statistics-based approach is that it might not be 100% accurate if map down to the individual providing data in these patterns. We have to very careful not to make mistakes about individuals because we make [an inference] about a population.
How do we think about privacy? We looked at it from the point of view of harms. There are a variety of ways in which results of big data can create harm, including inappropriate disclosures [of personal information], potential discrimination against groups, classes, or individuals, and embarrassment to individuals or groups.
We turned to what tech has to offer in helping to reduce harms. We looked at a number of technologies in use now. We looked at a bunch coming down the pike. We looked at several tech in use, some of which become less effective because of pervasivesness [of data] and depth of analytics.
We traditionally have controlled [data] collection. We have seen some data collection from cameras and sensors that people don’t know about. If you don’t know, it’s hard to control.
Tech creates many concerns. We have looked at methods coming down the pike. Some are more robust and responsive. We have a number of draft recommendations that we are still working out.
Part of privacy is protecting the data using security methods. That needs to continue. It needs to be used routinely. Security is not the same as privacy, though security helps to protect privacy. There are a number of approaches that are now used by hand that with sufficient research could be automated could be used more reliably, so they scale.
There needs to be more research and education about education about privacy. Professionals need to understand how to treat privacy concerns anytime they deal with personal data. We need to create a large group of professionals who understand privacy, and privacy concerns, in tech.
Technology alone cannot reduce privacy risks. There has to be a policy as well. It was not our role to say what that policy should be. We need to lead by example by using good privacy protecting practices in what the government does and increasingly what the private sector does.
Bill Press: We tried throughout to think of scenarios and examples. There’s a whole chapter [in the report] devoted explicitly to that.
They range from things being done today, present technology, even though they are not all known to people, to our extrapolations to the outer limits, of what might well happen in next ten years. We tried to balance examples by showing both benefits, they’re great, and they raise challenges, they raise the possibility of new privacy issues.
In another aspect, in Chapter 3, we tried to survey technologies from both sides, with both tech going to bring benefits, those that will protect [people], and also those that will raise concerns.
In our technology survey, we were very much helped by the team at the National Science Foundation. They provided a very clear, detailed outline of where they thought that technology was going.
This was part of our outreach to a large number of experts and members of the public. That doesn’t mean that they agree with our conclusions.
Eric Lander: Can you take everybody through analysis of encryption? Are people using much more? What are the limits?
Graham: The idea behind classical encryption is that when data is stored, when it’s sitting around in a database, let’s say, encryption entangles the representation of the data so that it can’t be read without using a mathematical algorithm and a key to convert a seemingly set of meaningless set of bits into something reasonable.
The same technology, where you convert and change meaningless bits, is used when you send data from one place to another. So, if someone is scanning traffic on internet, you can’t read it. Over the years, we’ve developed pretty robust ways of doing encryption.
The weak link is that to use data, you have to read it, and it becomes unencrypted. Security technologists worry about it being read in the short time.
Encryption technology is vulnerable. The key that unlocks the data is itself vulnerable to theft or getting the wrong user to decrypt.
Both problems of encryption are active topics of research on how to use data without being able to read it. There research on increasingly robustness of encryption, so if a key is disclosed, you haven’t lost everything and you can protect some of data or future encryption of new data. This reduces risk a great deal and is important to use. Encryption alone doesn’t protect.
Unknown Speaker: People read of breaches derived from security. I see a different set of issues of privacy from big data vs those in security. Can you distinguish them?
Bill Press: Privacy and security are different issues. Security is necessary to have good privacy in the technological sense if communications are insecure, they clearly can’t be private. This goes beyond, to where parties that are authorized, in a security sense, to see the information. Privacy is much closer to values. security is much closer to protocols.
Interesting thing is that this is less about purely tech elements — everyone can agree on right protocol, eventually. These things that go beyond and have to do with values.
Back in February, I reported that Esri would enable governments to open their data to the public.Today, the geographic information systems (GIS) software giant pushed ArcGIS Open Data live, instantly enabling thousands of its local, state and federal government users to open up the public data in their systems to the public, in just a few minutes.
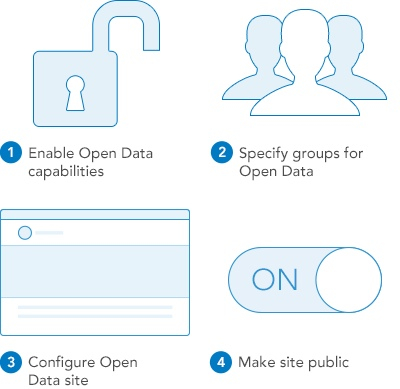
“Starting today any ArcGIS Online organization can enable open data, specify open data groups and create and publicize their open data through a simple, hosted and best practices web application,” wrote Andrew Turner, chief technology officer of Esri’s Research and Development Center in D.C., in a blog post about the public beta of Open Data ArcGIS. “Originally previewed at FedGIS ArcGIS Open Data is now public beta where we will be working with the community on feedback, ideas, improvements and integrations to ensure that it exemplifies the opportunity of true open sharing of data.”
Turner highlighted what this would mean for both sides of the open data equation: supply and demand.
Data providers can create open data groups within their organizations, designating data to be open for download and re-use, hosting the data on the ArcGIS site. They can also create public microsites for the public to explore. (Example below.) Turner also highlighted the code for Esri’s open-source GeoPortal Server on Github as a means to add metadata to data sets.
Data users, from media to developers to nonprofits to schools to businesses to other government entities, will be able to download data in common open formats, including KML, Spreadsheet (CSV), Shapefile, GeoJSON and GeoServices.
“As the US Open Data Institute recently noted, [imagine] the impact to opening government data if software had ‘Export as JSON’ by default,” wrote Turner.
“That’s what you now have. Users can also subscribe to the RSS feed of updates and comments about any dataset in order to keep up with new releases or relevant supporting information. As many of you are likely aware, the reality of these two perspectives are not far apart. It is often easiest for organizations to collaborate with one another by sharing data to the public. In government, making data openly available means departments within the organization can also easily find and access this data just as much as public users can.”
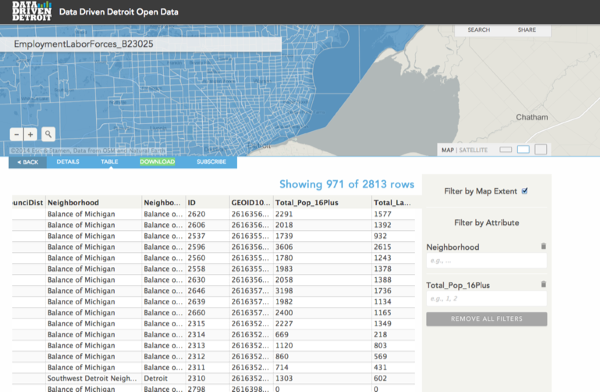
Turner highlighted what an open data site would look like in the wild:
“Data Driven Detroit a great example of organizations sharing data. They were able to leverage their existing data to quickly publish open data such as census, education or housing. As someone who lived near Detroit, I can attest to the particular local love and passion the people have for their city and state – and how open data empowers citizens and businesses to be part of the solution to local issues.
In sum, this feature could, as I noted in February, could mean a lot more data is suddenly available for re-use. When considered in concert with Esri’s involvement in the White House’s Climate Data initiative, 2014 looks set to be a historic year for the mapping giant.
It also could be a banner year for open data in general, if governments follow through on their promises to release more of it in reusable forms. By making it easy to upload data, hosting it for free and publishing it in the open formats developers commonly use in 2014, Esri is removing three major roadblocks governments face after a mandate to “open up” come from a legislature, city council, or executive order from the governor or mayor’s office.
“The processes in use to publish open data are unreasonably complicated,” said Waldo Jacquith, director of the U.S. Open Data Institute, in an email.
“As technologist Dave Guarino recently wrote, basically inherent to the process of opening data is ETL: “extract-transform-load” operations. This means creating a lot of fragile, custom code, and the prospect of doing that for every dataset housed by every federal agency, 50 states, and 90,000 local governments is wildly impractical.
Esri is blazing the trail to the sustainable way to open data, which is to open it up where it’s already housed as closed data. When opening data is as simple as toggling an “open/closed” selector, there’s going to be a lot more of it. (To be fair, there are many types of data that contain personally identifiable information, sensitive information, etc. The mere flipping of a switch doesn’t address those problems.)
Esri is a gold mine of geodata, and the prospect of even a small percentage of that being released as open data is very exciting.”
Video of the talk is below, along with the slides I used. You can view all of the videos from the workshop, along with the public plenary on Monday evening, on YouTube or at the workshop page.
Here’s the presentation, with embedded hyperlinks to the organizations, projects and examples discussed:
For more on the “Second Machine Age” referenced in the title, read the new book by Erik Brynjolfsson and Andrew McAfee.
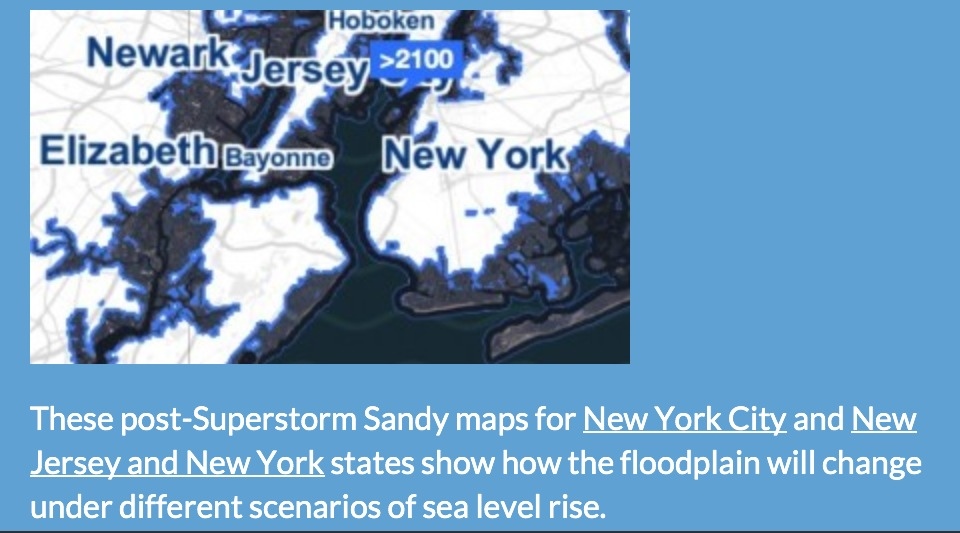
Today, the White House launched an effort to engage the nation’s private sector to create tools and resources that increase the resiliency of communities to extreme weather events.
In the pilot phase, more data related to coastal flooding are now on Data.gov, with more on projected sea level rise and estimated impacts to follow. More government data from NOAA, NASA, the U.S. Geological Survey, the Department of Defense, and other federal agencies will be featured on climate.data.gov. NOAA and NASA have will host a challenge for researchers and developers “to create data-driven simulations to help plan for the future and to educate the public about the vulnerability of their own communities to sea level rise and flood events.”
As the Associated Press reported, another effort plans to add sensors on city buses in Philadelphia to collect data. Should the effort go forward and be expanded, it will provide an important focus for sensor journalism.
A number of private sector companies have announced their involvement. part. Later today, The World Bank will publish a new field guide for the “Open Data for Resilience Initiative.” Esri will partner with a dozen cities across the USA to challenge developers to use its ArcGIS platform. Google will donate one petabyte of storage for climate data and 50 million hours of processing time on the Google Earth Engine.
In sum, the focus on this component of the initiative is on helping people understand and plan for potential changes to their communities, as opposed to using data to make a case to the public about the source or science of climate change. While it is no substitute for increased public understanding of the latter, improving local resiliency to severe weather through data-driven analyses is a sufficiently pragmatic, useful approach that it might just have an impact.
The White House will host a forum at 5 PM in DC today featuring talks by officials and executives from the agencies and companies involved. More details and context on the new climate data initiative are available at the White House blog.
The privacy and civil liberties board’s report is strongly critical of the impact that mass surveillance has upon the privacy and civil liberties of American citizens, along with billions of other people around the world.
“The Section 215 bulk telephone records program lacks a viable legal foundation under Section 215, implicates constitutional concerns under the First and Fourth Amendments, raises serious threats to privacy and civil liberties as a policy matter, and has shown only limited value. As a result, the Board recommends that the government end the program.”
PCLOB Board Members meet with President Obama on June 21, 2013. Photo by Pete Souza.
While President Obama met with the board and heard their recommendations prior to his speech last week, his administration is disputing its legal analysis.
“We disagree with the board’s analysis on the legality,” said Caitlin Hayden, spokeswoman for the White House National Security Council, in an e-mail to Bloomberg News. “The administration believes that the program is lawful.”
House Intelligence Committee Chairman Mike Rogers (R-MI) was also critical of the report’s findings. “I am disappointed that three members of the Board decided to step well beyond their policy and oversight role and conducted a legal review of a program that has been thoroughly reviewed,” he said in a statement.
The Electronic Frontier Foundation hailed the report as a vindication of its position on the consitutionality of the programs.
“The board’s other recommendations—increasing transparency and changing the FISA court in important ways—similarly reflect a nearly universal consensus that significant reform is needed,” wrote Mark Rumold, a staff attorney. “In the coming weeks, PCLOB is set to release a second report addressing the NSA’s collection under Section 702 of the FISA Amendments Act. We hope that the board will apply similar principles and recognize the threat of mass surveillance to the privacy rights of all people, not just American citizens.”
One of the most important open government data efforts in United States history came into being in 1993, when citizen archivist Carl Malamud used a small planning grant from the National Science Foundation to license data from the Securities and Exchange Commission, published the SEC data on the Internet and then operated it for two years. At the end of the grant, the SEC decided to make the EDGAR data available itself — albeit not without some significant prodding — and has continued to do so ever since. You can read the history behind putting periodic reports of public corporations online at Malamud’s website, public.resource.org.
Two decades later, Malamud is working to make the law public, reform copyright, and free up government data again, buying, processing and publishing millions of public tax filings from nonprofits to the Internal Revenue Service. He has made the bulk data from these efforts available to the public and anyone else who wants to use it.
“This is exactly analogous to the SEC and the EDGAR database,” Malamud told me, in an phone interview last year. The trouble is that data has been deliberately dumbed down, he said. “If you make the data available, you will get innovation.”
November Form 990s now ready. http://t.co/HDoMzPjpY0 We have 7,335,804 Form 990s available. *STILL* no word from the IRS.
Making millions of Form 990 returns free online is not a minor public service. Despite many nonprofits file their Form 990s electronically, the IRS does not publish the data. Rather, the government agency releases images of millions of returns formatted as .TIFF files onto multiple DVDs to people and companies willing and able to pay thousands of dollars for them. Services like Guidestar, for instance, acquire the data, convert it to PDFs and use it to provide information about nonprofits. (Registered users view the returns on their website.)
As Sam Roudman reported at TechPresident, Luke Rosiak, a senior watchdog reporter for the Washington Examiner, took the files Malamud published and made them more useful. Specifically, he used credits for processing that Amazon donated to participants in the 2013 National Day of Civic Hacking to make the .TIFF files text-searchable. Rosiak then set up CItizenAudit.org a new website that makes nonprofit transparency easy.
“This is useful information to track lobbying,” Malamud told me. “A state attorney general could just search for all nonprofits that received funds from a donor.”
Malamud estimates nearly 9% of jobs in the U.S. are in this sector. “This is an issue of capital allocation and market efficiency,” he said. “Who are the most efficient players? This is more than a CEO making too much money — it’s about ensuring that investments in nonprofits get a return.
“I think inertia is behind the delay,” he told me, in our interview. “These are not the expense accounts of government employees. This is something much more fundamental about a $1.6 trillion dollar marketplace. It’s not about who gave money to a politician.”
If I order these IRS DVDs, my cost is $2910. Media and gov get them free, but none of them lifting a finger to help. http://t.co/B6m5VECV1O
When asked for comment, a spokesperson for the White House Office of Management and Budget said that the IRS “has been engaging on this topic with interested stakeholders” and that “the Administration’s Fiscal Year 2014 revenue proposals would let the IRS receive all Form 990 information electronically, allowing us to make all such data available in machine readable format.”
Today, Malamud sent a letter of complaint to Howard Shelanski, administrator of the Office of Information and Regulatory Affairs in the White House Office of Management and Budget, asking for a review of the pricing policies of the IRS after a significant increase year-over-year. Specifically, Malamud wrote that the IRS is violating the requirements of President Obama’s executive order on open data:
The current method of distribution is a clear violation of the President’s instructions to
move towards more open data formats, including the requirements of the May 9, 2013 Executive Order making “open and machine readable the new default for government
information.”
I believe the current pricing policies do not make any sense for a government
information dissemination service in this century, hence my request for your review.
There are also significant additional issues that the IRS refuses to address, including
substantial privacy problems with their database and a flat-our refusal to even
consider release of the Form 990 E-File data, a format that would greatly increase the
transparency and effectiveness of our non-profit marketplace and is required by law.
It’s not clear at all whether the continued pressure from Malamud, the obvious utility of CitizenAudit.org or the bipartisan budget deal that President Obama signed in December will push the IRS to freely release open government data about the nonprofit sector,
The furor last summer over the IRS investigating the status of conservative groups claimed tax-exempt status, however, could carry over into political pressure to reform. If political groups were tax-exempt and nonprofit e-file data were published about them, it would be possible for auditors, journalists and Congressional investigators to detect patterns. The IRS would need to be careful about scrubbing the data of personal information: last year, the IRS mistakenly exposed thousands of Social Security numbers when it posted 527 forms online — an issue that Malamud, as it turns out, discovered in an audit.
“This data is up there with EDGAR, in terms of its potential,” said Malamud. “There are lots of databases. Few are as vital to government at large. This is not just about jobs. It’s like not releasing patent data.”
If the IRS were to modernize its audit system, inspector generals could use automated predictive data analysis to find aberrations to flag for a human to examine, enabling government watchdogs and investigative journalists to potentially detect similar issues much earlier.
That level of data-driven transparency remains in the future. In the meantime, CitizenAudit.org is currently running on a server in Rosiak’s apartment.
Whether the IRS adopts it as the SEC did EDGAR remains to be seen.