Dear Secretary Psaki and the Office of the Press Secretary, My name is Alexander B Howard; you may have noticed me tweeting at you this past couple months during the transition and now the administration. I came to DC over … Continue reading

Dear Secretary Psaki and the Office of the Press Secretary, My name is Alexander B Howard; you may have noticed me tweeting at you this past couple months during the transition and now the administration. I came to DC over … Continue reading
Yesterday, the United States Freedom of Information Act Advisory Committee met at the National Archives in Washington and approved a series of recommendations that would, if implemented, dramatically improve public access to public information. And in May, it will consider … Continue reading

Like Google, Facebook and Twitter, Snapchat now has an online political ad library. That’s good news: every technology company that accept money to run issues and campaign ads should have a political ad file – particularly one that has aspirations … Continue reading

For a decade, I’ve tracked the contours of open data, digital journalism, open source software and open government, publishing research on the art and science of data journalism that explored and tied together those threads.
This week, I’m proud to announce that a new book chapter on open data, journalists, and the media that I co-authored with data journalism advisor Eva Constantaras has been published online as part of “The State of Open Data: Histories and Horizons!”
We joined 43 other authors in a 18-month project that reflected on “10 years of community action and review the capacity of open data to address social and economic challenges across a variety of sectors, regions, and communities.”
The publication and the printed review copy I now possess is the end of a long road.
Back in January 2018, I asked a global community of data journalists, open government advocates, watchdogs and the public for help documenting the “State of Open Data” and journalism for a new project for Open Data for Development. While I was at the Sunlight Foundation, I seeded the initial network scan on journalists, media and open data.
Over the past year, people and organizations from around the world weighed in – & Eva Constantaras joined me as co-editor & lead author, creating a “network scan” of the space. The writing project traveled with me, after I left Sunlight, and over this winter we edited and synthesized the scan into a polished chapter.
The book was originally going to be introduced at the 5th International Open Government Data Conference in Buenos Aires, in the fall of 2018, but will instead be officially launched at the Open Government Partnership’s global summit in Ottawa, Canada at the end of May 2019.
The book, which was funded by the International Research Centre and supported by the Open Data for Development (OD4D) Network. As a result of that support, “The State of Open Data” was also published in print by African Minds, from whom it may also be purchased. (While I was paid to edit and contribute, I don’t receive any residuals.)
Last night, I joined Tim Davies and other authors at the OpenGov Hub in DC to talk about the book & our chapters. Video of Davies, who managed to cover a tremendous amount of ground in ten minutes, is embedded below.
Thank you to everyone who contributed, commented and collaborated in this project, which will inform the public, press and governments around the world.

What’s next for open data in the United States? That was the open question posed at the Center for Data Innovation (CDI) last week, where a panel of industry analysts and experts gathered to discuss the historic open government data … Continue reading
 On December 21, 2018, the United States House of Representatives voted to enact H.R. 4174, the Foundations for Evidence-Based Policymaking Act of 2017, in a historic win for open government in the United States of America.
On December 21, 2018, the United States House of Representatives voted to enact H.R. 4174, the Foundations for Evidence-Based Policymaking Act of 2017, in a historic win for open government in the United States of America.
The Open, Public, Electronic, and Necessary Government Data Act (AKA the OPEN Government Data Act) is about to become law as a result. This codifies two canonical principles for democracy in the 21st century:
For the full backstory on what’s in the bill and how it came to pass, read yesterday’s feature.
It’s worth noting that last minute objection did result in two amendments that the Senate had to act upon. Thankfully, on Saturday, December 22nd, the Senate acted, passing the resolution required to send the bill onwards to the president’s desk.
Here’s what changed: First, the text of Title I was amended so that it only applied to CFO Act agencies, not the Federal Reserve or smaller agencies. Title II (the Open Government Act) still applies to all federal agencies.

Second, there was a carve out in Title I “for data that does not concern monetary policy,” which relates to the Federal Reserve, among others.

While the shift weakened the first title of the bill a bit, this was still a historic moment: Congress has passed a law to make open data part of of the US Code.
While the United States is not the first or even the second democracy to pass an open data law – France and Germany have that distinction – this is a welcome advance, codifying the open government data policies, practices, roles and websites (looking at you, Data.gov) that the federal government had adopted over the past decade.
Open government activists, advocates and champions continue to celebrate, online and off.
Victory! Last night the @DataCoalition got the #OPENGovData Act through the Senate, as part of H.R. 4174. Expected to sail through the House TODAY. Sets a presumption, in law, that govt info ought to be published as #opendata, using data standards. https://t.co/jTdM1rIVTW
— Hudson Hollister (@hudsonhollister) December 20, 2018
https://platform.twitter.com/widgets.js
#Opendata will soon be the way our government publishes information by default!! What a great day for #opendata #opengov #transparency! This would not have been possible w/o @SpeakerRyan @PattyMurray @SenBrianSchatz @SenSasse @RepDerekKilmer. Thank you! #OPENGovDataAct (HR 4174)
— Data Coalition (@DataCoalition) December 21, 2018
https://platform.twitter.com/widgets.js
Merry Christmas to me! The U.S. Congress has passed an open data law. pic.twitter.com/tDwo8j8UCB
— Rebecca Williams (@internetrebecca) December 21, 2018
https://platform.twitter.com/widgets.js
Excited to see the Open Government Data Act pass the House today! H.R. 4174 will enable libraries to provide businesses, researchers and students with valuable data that fuels innovation and economic growth. #OPENGovData #opendata
— Gavin Baker (@OpenGavin) December 21, 2018
https://platform.twitter.com/widgets.js
“The bipartisan passage of the Foundations for Evidence-Based Policymaking Act is a significant step toward a more efficient, more effective government that uses evidence and data to improve results for the American people,” said Michele Jolin, CEO and co-founder of Results for America, in a statement. “We commend Speaker Ryan, Senator Murray and their bipartisan colleagues in both chambers for advancing legislation that will help build evidence about the federally-funded practices, policies and programs that deliver the best outcomes. By ensuring that each federal agency has an evaluation officer, an evaluation policy and evidence-building plans, we can maximize the impact of public investments.”
“The OPEN Government Data Act will ensure that the federal government releases valuable data sets, follows best practices in data management, and commits to making data available to the public in a non-proprietary and electronic format,” said Daniel Castro, in a statement. “Today’s vote marks a major bipartisan victory for open data. This legislation will generate substantial returns for the public and private sectors alike in the years to come.”
“The passage of the OPEN Government Data Act is a win for the open data community”, said Sarah Joy Hays, Acting Executive Director of the Data Coalition, in a statement. “The Data Coalition has proudly supported this legislation for over three years, along with dozens of other organizations. The bill sets a presumption that all government information should be open data by default: machine-readable and freely-reusable. Ultimately, it will improve the way our government runs and serves its citizens. This would not have been possible without the support of Speaker Paul Ryan (WI-1-R), Senators Patty Murray (WA-D), Brian Schatz (HI-D), Ben Sasse (NE-R), and Rep. Derek Kilmer (WA-6-D). Our Coalition urges the President to promptly sign this open data bill into law.”
Congratulations to everyone who has pushed for this outcome for years.
[Image Credit: Sunlight Foundation]
This post has been updated, and corrected: France was ahead of Germany in enacting an open data law.
The arc of open government in United States is long, but perhaps it will bend towards transparency and accountability as 2018 comes to a close, in an unlikely moment in our history. After years of dedicated effort by advocates and bipartisan leadership in both houses of Congress, the Open, Public, Electronic, and Necessary Government Data Act (AKA the OPEN Government Data Act) is about to become law after the United States Senate passed the bill as part of H.R. 4174 on December 19.
Senator Brian Schatz (D-HI) shared the news in a tweet last night:
We just passed a bill that requires all data the govt collects (that isn’t secret or private) to be machine readable and interoperable. It’s data that taxpayers paid for and they deserve access – weather, traffic, census, budget numbers – it’s your info and you should have it.
— Brian Schatz (@brianschatz) December 19, 2018
…followed by Representative Derek Killmer (D-
Last night the Senate passed a bill I introduced in the House called the Open Government Data Act! There are so many possibilities for our economy when folks can access data they paid to develop and fund through the nation’s largest angel investor, Unce Sam. https://t.co/BvMX54mcCY
— Rep. Derek Kilmer (@RepDerekKilmer) December 20, 2018
Here’s Schatz speaking about the bill at a Data Coalition event last winter:
Two steps remain: passage of the bill in the House and President Donald J. Trump signing it into law. Barring a scheduling issue or unexpected change (keep an eye out for shenanigans on the House floor today), the nation is close to a historic codification of two powerful principles:
Along with making open government data the default in U.S. government and requiring the White House Office of Management and Budget to oversee enterprise data inventories for every agency, the bill would require federal agencies to do the following, as listed in the summary from the Law Library of Congress:
This bill requires departments and agencies identified in the Chief Financial Officers Act to submit annually to the Office of Management and Budget (OMB) and Congress a plan for identifying and addressing policy questions relevant to the programs, policies, and regulations of such departments and agencies.
The plan must include: (1) a list of policy-relevant questions for developing evidence to support policymaking, and (2) a list of data for facilitating the use of evidence in policymaking.
The OMB shall consolidate such plans into a unified evidence building plan.
The bill establishes an Interagency Council on Evaluation Policy to assist the OMB in supporting government-wide evaluation activities and policies. The bill defines “evaluation” to mean an assessment using systematic data collection and analysis of one or more programs, policies, and organizations intended to assess their effectiveness and efficiency.
Each department or agency shall designate a Chief Evaluation Officer to coordinate evidence-building activities and an official with statistical expertise to advise on statistical policy, techniques, and procedures.
The OMB shall establish an Advisory Committee on Data for Evidence Building to advise on expanding access to and use of federal data for evidence building.
Open, Public, Electronic, and Necessary Government Data Act or the OPEN Government Data Act
This bill requires open government data assets to be published as machine-readable data.
Each agency shall: (1) develop and maintain a comprehensive data inventory for all data assets created by or collected by the agency, and (2) designate a Chief Data Officer who shall be responsible for lifecycle data management and other specified functions.
The bill establishes in the OMB a Chief Data Officer Council for establishing government-wide best practices for the use, protection, dissemination, and generation of data and for promoting data sharing agreements among agencies.
While the United States would not be not the first democracy to pass such a law, it would be a welcome advance, codifying many aspects of the open government data policies that have been developed and promulgated in the federal government over the past decade.
This was no accident of fate or circumstance: This bill, which was previously passed by the House last month, was sponsored by the Speaker of the House, Paul Ryan. It’s an important element of his legislative legacy, and one that can and should earn praise – unlike other aspects of his time with the gavel.
It’s taken years of advocacy and activism by a broad coalition to get here, including the Sunlight Foundation, the EFF, Business Software Alliance, Center for Data Innovation, the Scholarly Publishing and Academic Resources Coalition, American Library Association, the R Street Institute, among many others, and bipartisan efforts on both sides of the aisle. Senator Ben Sasse (R-NE) co-sponsored the OGDA in the Senate, with 5 others, and former Representative Blake Farenthold (R-TX) cosponsored it in House, with 12 others.
That original bill almost made it into law in 2016, when the Senate passed OGDA by unanimous consent, but the House didn’t move it before the end of the 115th Congress. In September 2017, when it was poised to pass Congress as part of the National Defense Authorization Act., before it was stripped from the final version.
In October 2017, the text of the Open Government Data Act, however, was incorporated into H.R. 4174, the Foundations for Evidence-Based Policymaking Act of 2017,
The new bipartisan, bicameral companion legislation was introduced on October 31, 2017 by Speaker of the House Paul Ryan (R-WI) and Senator Patty Murray (D-WA) to enact the recommendations contained in the final report from the Commission of Evidenced-Based Policy.
While it has been watered down a bit, what I argued then is still true today: the bill “offers a genuine opportunity to not only improve how the nation makes decisions but embed more openness into how the federal government conducts the public’s business.”
The addition of OGDA into that bill was “an important endorsement of open government data by one of the most powerful politicians in the world” and “a milestone for the open movement, an important validation of this way of making public policy, and the fundamental principles of data-driven 21st century governance.”
The OGDA was one of the primary legislative priorities for me during my years as a senior analyst and then deputy director at the Sunlight Foundation, along with Freedom of Information Act Reform and Honest Ads Act.
I picked up the transparency baton on OGDA from former Sunlight analyst Matt Rumsey, Sunlight federal policy manager Sean Vitka, OpenGov Foundation founder Seamus Kraft, and Data Coalition founder Hudson Hollister, who drafted the original open data bill, working to make the principle that “public data created with taxpayer dollars should be available to the public in open, machine-readable forms when doing so does not damage privacy or national security” the law.
This is a huge win for public access to public information that every American can and should celebrate today. Special thanks for this victory are due to Christian Hoehner, policy director for the Data Coalition, who did extraordinary yeoman’s work getting this through Congress, Sasha Moss of the R Street Institute, Hollister, Daniel Schuman of Demand Progress, Daniel Castro and Joshua New at the Center for Data Innovation, and Gavin Baker from the American Library Association, some with whom I went to Congress with me to meet with staff over the years and advocated for the bill on and offline.
The passage of this bill won’t mean that the scanned images of spreadsheets that agencies still send in response to FOIA requests will magically go away tomorrow, but journalists, watchdogs and the public can now tell civil servants that they’re now behind the times: open government data is now the default in the USA! Please publish our data on the agency website in a structured format and let the public know.
[Image Credit: Sunlight Foundation]

Imagine searching Facebook, Google or Twitter for the status of a bill before Congress and getting an instant result. That future is now here, but it’s not evenly implemented yet.
When the Library of Congress launched Congress.gov in 2012, they failed to release the data behind it. Yesterday, that changed when the United States Congress started releasing data online about the status of bills.
For the open government advocates, activists and civic hackers that have been working for over a decade for this moment, seeing Congress turn on the data tap was a historic shift.
It took 14 years 9 months 6 days after I asked: Congress is now publishing actual data on the status of legislation. https://t.co/ITtDev12Xs
— Joshua Tauberer (@JoshData) February 24, 2016
//platform.twitter.com/widgets.js
Congressional leaders from both sides of the aisle applauded the release of House and Senate bill status information by the U.S. Government Printing Office and Library of Congress.
“Today’s release of bill status information via bulk download is a watershed moment for Congressional transparency,” said House Majority Leader Kevin McCarthy (R-CA), in a statement. “By modernizing our approach to government and increasing public access to information, we can begin to repair the relationship between the people and their democratic institutions. The entire Congressional community applauds the dedication of the Legislative Branch Bulk Data Task Force, the Office of the Clerk, the House Appropriations Committee, GPO, and the Library of Congress, which worked together to make this progress possible.”
“Building off previous releases of bills and summaries, today’s release of bill status information largely completes the overarching goal of providing bulk access to all the legislative data that traditionally has been housed on Thomas.gov and now also resides on Congress.gov,” said Democratic Whip Steny Hoyer (D-MD). “This is a major accomplishment that has been many years in the making. It goes a long way toward making Congress more transparent and accessible to innovation through third party apps and systems. I applaud the dedicated civil servants who made this possible at the Legislative Branch service agencies, and I want to thank the Bulk Data Task Force for their leadership in this effort. While this largely completes a major goal of the Task Force, I look forward to continuing to workwith them to further modernize the U.S. Congress.”
The impact of open government data releases depend upon publicy and political agency. Releasing the states of bills before Congress in a way that can be baked in by third party apps and services is a critical, laudable step in that direction, but much more remains to be done in making the data more open and putting it to use and re-use. If the Library of Congress opens up an application programming interface for the data that supplies both Congress.gov and the public, it would help to reduce the asynchrony of legislative information between the public and elites who can afford to pay for Politico’s Legislative Compass or Quorum Analytics that is the status quo today.
In an era when Congress job approval ratings and trust in government are at historic lows, the shift didn’t make news beyond the Beltway. Govtrack.us, which is based upon data scraped from the Library of Congress, has been online for years. Until this XML data is used by media and technology companies in ways that provide the public with more understanding of what Congress is doing on their behalf and give them more influence in that legislative process, that’s unlikely to change quickly.
This is the week for seeking feedback on open government in the United States. 4 days ago, the White House published a collaborative online document that digitized the notes from an open government workshop held during Sunshine Week in March. Today, Abby Paulson from OpenTheGovernment.org uploaded a final draft of a Model National Action Plan to the Internet, as a .doc. I’ve uploaded it to Scribd and embedded it below for easy browsing. Nelson shared the document over email with people who contributed to the online draft.
Thank you so much for contributing to the civil society model National Action Plan. The Plan has made its way from Google Site to Word doc (attached)! We will share these recommendations with the White House, and I encourage you to share your commitments with any government contacts you have. If you notice any errors made in the transition from web to document, please let me know. If there are any other organizations that should be named as contributors, we will certainly add them as well. The White House’s consultation for their plan will continue throughout the summer, so there are still opportunities to weigh in. Additional recommendations on surveillance transparency and beneficial ownership are in development. We will work to secure meetings with the relevant agencies and officials to discuss these recommendations and make a push for their inclusion in the official government plan. So, expect to hear from us in the coming weeks!
Yesterday, I wrote up 15 key insights from the Pew Internet and Life Project’s new research on the American public’s attitude towards open data and open government. If you missed it, what people think about government data and the potential impact of releasing it is heavily influenced by the prevailing low trust in government and their politics.
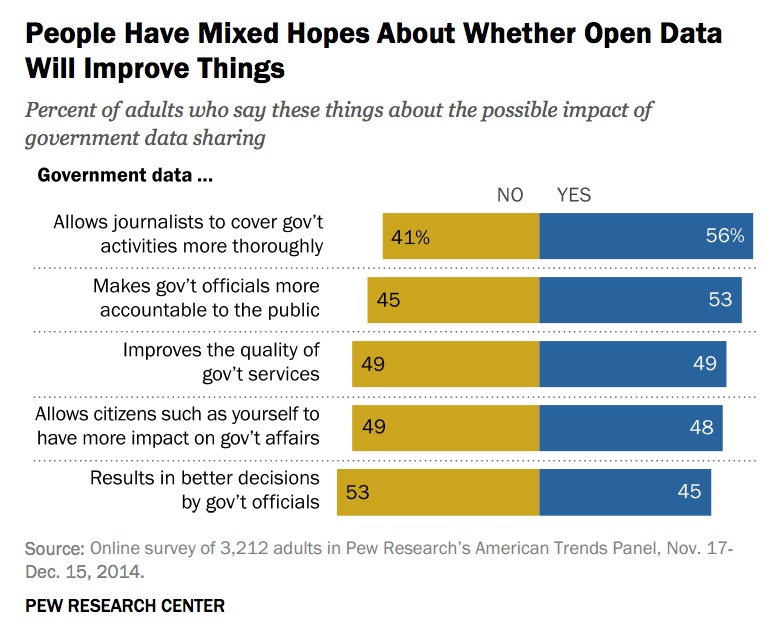
Media coverage of the survey reflected the skepticism of the reporters (“Most Americans don’t think government transparency matters a damn“) or of the public (“Who cares about open data” and “Americans not impressed by open government initiatives“). This photo by Pete Souza below might be an apt image for this feeling:

Other stories pulled out individual elements of the research (“Open data on criminals and teachers is a-okay, say most US citizens” or mixed results (“People Like U.S. Open Data Initiatives, But Think Government Could Do More” and “Sorry, open data: Americans just aren’t that into you“) or general doubts about an unfamiliar topic (“Many Americans Doubt Government Open Data Efforts“). At least one editor’s headline suggested that the results were an indictment of everything government does online: (“Americans view government’s online services and public data sharing as a resounding ‘meh’.) Meh, indeed.
As usual, keep a salt shaker handy as you browse the headlines and read the original source. The research itself is more nuanced than those headlines suggest, as my interview with the lead researcher on the survey, John Horrigan, hopefully made clear.
Over at TechPresident, editor-in-chief Micah Sifry saw a glass half full:
- Digging deeper into the Pew report, it’s interesting to find that beyond the “ardent optimists” (17% of adults) who embrace the benefit of open government data and use it often, and the “committed cynics” (20%) who use online government resources but think they aren’t improving government performance much, there’s a big group of “buoyant bystanders” (27%) who like the idea that open data can improve government’s performance but themselves aren’t using the internet much to engage with government. (Heads up Kate Krontiris, who’s been studying the “interested bystander.”)
- It’s not clear how much of the bystander problem is also an access problem. According to a different new analysis done by the Pew Research Center, about five million American households with school-age children–nearly one in five–do not have high-speed internet access at home. This “broadband gap” is worst among households with incomes under $50,000 a year.
Reaction from foundations that have advocated, funded or otherwise supported open government data efforts went deeper. Writing for the Sunlight Foundation, communications director Gabriela Schneider saw the results from the survey in a rosy (sun)light, seeing public optimism about open government and open data.
People are optimistic that open data initiatives can make government more accountable. But, many surveyed by Pew are less sure open data will improve government performance. Relatedly, Americans have not quite engaged very deeply with government data to monitor performance, so it remains to be seen if changes in engagement will affect public attitudes.
That’s something we at Sunlight hope to positively affect, particularly as we make new inroads in setting new standards for how the federal government discloses its work online. And as Americans shift their attention away from Congress and more toward their own backyards, we know our newly expanded work as part of the What Works Cities initiative will better engage the public, make government more effective and improve people’s lives.
Jonathan Sotsky, director of strategy and assessment for the Knight Foundation, saw a trust conundrum for government in the results:
Undoubtedly, a greater focus is needed on explaining to the public how increasing the accessibility and utility of government data can drive accountability, improve government service delivery and even provide the grist for new startup businesses. The short-term conundrum government data initiatives face is that while they ultimately seek to increase government trustworthiness, they may struggle to gain structure because the present lack of trust in government undermines their perceived impact.
Steven Clift, the founder of e-democracy.org, views this survey as a wakeup call for open data advocates.
One reason I love services like CityGram, GovDelivery, etc. is that they deliver government information (often in a timely way) to the public based on their preferences/subscriptions. As someone who worked in “e-government” for the State of Minnesota, I think most people just want the “information” that matters to them and the public has no particular attachment to the idea of “open data” allowing third parties to innovate or make this data available. I view this survey as a huge wake up call to #opengov advocates on the #opendata side that the field needs to provide far more useful stuff to the general public and care a lot more about outreach and marketing to reach people with the good stuff already available.
Mark Headd, former chief data officer for the City of Philadelphia and current developer evangelist for Accela software, saw the results as a huge opportunity to win hearts and minds:
The modern open data and civic hacking movements were largely born out of the experience of cities. Washington DC, New York City and Chicago were among the first governments to actively recruit outside software developers to build solutions on top of their open data. And the first governments to partner with Code for America – and the majority over the life of the organization’s history – have been cities.
How do school closings impact individual neighborhoods? How do construction permit approvals change the character of communities? How is green space distributed across neighborhoods in a city? Where are vacant properties in a neighborhood – who owns them and are there opportunities for reuse?
These are all the kinds of questions we need people living and working in neighborhoods to help us answer. And we need more open data from local governments to do this.
If you see other blog posts or media coverage that’s not linked above, please let me know. I storified some reactions on Twitter but I’m certain that I missed conversations or opinions.
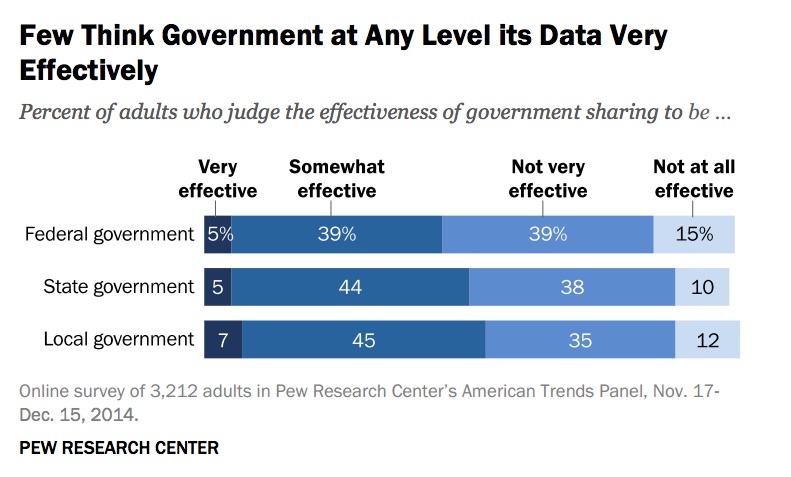
There are two additional insights from Pew that I didn’t write about yesterday that are worth keeping in mind with respect to how how Americans are thinking about the release of public data back to the public. First, it’s unclear whether the public realizes they’re using apps and services built upon government data, despite sizable majorities doing so.
Majorities of Americans use apps & services that use #opendata; Just 5% think govt shares well http://t.co/e11502mCUZ pic.twitter.com/zdwYzpnaJM
— Alex Howard (@digiphile) April 21, 2015
Second, John Horrigan told me that survey respondents universally are not simply asking for governments to make the data easier to understand so that they can figure out what I want to figure out: what people really want is intermediaries to help them make sense of the data.
“We saw a fair number of people pleading in comments for better apps to make the data make sense,” said Horrigan. “When they went online, they couldn’t get budget data to work. When the found traffic data, couldn’t make it work. There were comments on both sides of the ledger. Those that think government did an ok job wish they did this. Those that thin government is doing a horrible job also wish they did this.”
This is the opportunity that Headd referred to, and the reason that data journalism is the critical capacity that democratic governments which genuinely want to see returns on accountability and transparency must ensure can flourish in civil society.
If a Republican is elected as the next President of the United States, we’ll see if public views shift on other fronts.
