
Yesterday, the United States Freedom of Information Act Advisory Committee met at the National Archives in Washington and approved a series of recommendations that would, if implemented, dramatically improve public access to public information. And in May, it will consider … Continue reading
Tag Archives: open government data
US FOIA Advisory Committee considers recommendations to part the rising curtains of secrecy

Government secrecy, as measured by censorship or non-responsiveness under the Freedom of Information Act, is at an all-time high during the Trump administration. The Freedom of Information Act is getting worse under Trump for a variety of reasons. Continued secrecy … Continue reading
New “State of Open Data” book captures a global zeitgeist around public access to information and use

For a decade, I’ve tracked the contours of open data, digital journalism, open source software and open government, publishing research on the art and science of data journalism that explored and tied together those threads.
This week, I’m proud to announce that a new book chapter on open data, journalists, and the media that I co-authored with data journalism advisor Eva Constantaras has been published online as part of “The State of Open Data: Histories and Horizons!”
We joined 43 other authors in a 18-month project that reflected on “10 years of community action and review the capacity of open data to address social and economic challenges across a variety of sectors, regions, and communities.”
The publication and the printed review copy I now possess is the end of a long road.
Back in January 2018, I asked a global community of data journalists, open government advocates, watchdogs and the public for help documenting the “State of Open Data” and journalism for a new project for Open Data for Development. While I was at the Sunlight Foundation, I seeded the initial network scan on journalists, media and open data.
Over the past year, people and organizations from around the world weighed in – & Eva Constantaras joined me as co-editor & lead author, creating a “network scan” of the space. The writing project traveled with me, after I left Sunlight, and over this winter we edited and synthesized the scan into a polished chapter.
The book was originally going to be introduced at the 5th International Open Government Data Conference in Buenos Aires, in the fall of 2018, but will instead be officially launched at the Open Government Partnership’s global summit in Ottawa, Canada at the end of May 2019.
The book, which was funded by the International Research Centre and supported by the Open Data for Development (OD4D) Network. As a result of that support, “The State of Open Data” was also published in print by African Minds, from whom it may also be purchased. (While I was paid to edit and contribute, I don’t receive any residuals.)
Last night, I joined Tim Davies and other authors at the OpenGov Hub in DC to talk about the book & our chapters. Video of Davies, who managed to cover a tremendous amount of ground in ten minutes, is embedded below.
Thank you to everyone who contributed, commented and collaborated in this project, which will inform the public, press and governments around the world.
The state of open government (data) remains divided, at risk, and underfunded

What’s next for open data in the United States? That was the open question posed at the Center for Data Innovation (CDI) last week, where a panel of industry analysts and experts gathered to discuss the historic open government data … Continue reading
15 key insights from the Pew Internet and Life Project on the American public, open data and open government
Today, a new survey released by the Pew Research Internet and Life Project provided one of the most comprehensive snapshots into the attitudes of the American public towards open data and open government to date. In general, more people surveyed are guardedly optimistic about the outcomes and release of open data, although that belief does vary with their political views, trust in government, and specific areas. (Full disclosure: I was consulted by Pew researchers regarding useful survey questions to pose.)

“Trust in government is the reference that people bring to their answers on open government and open data,” said John Horrigan, the principal researcher on the survey, in an interview. “That’s the frame of reference people bring. A lot of people still aren’t familiar with the notion, and because they don’t have a framework about open data, trust dominates, and you get the response that we got.”

While majorities of the American public use applications and services that use government data, from GPS to weather to transit to health apps, relatively few are aware that data produced and released by government drives them.
“The challenge for activists or advocates in this space will be to try to make the link between government data and service delivery outcomes,” said Horrigan. “If the goals are to make government perform better and maybe reverse the historic tide of lowered trust, then the goal is to make improvements real in delivery. If this is framed just as argument over data quality, it would go into an irresolvable back and forth into the quality of government data collection. If you can cast it beyond whether unemployment statistics are correct or not but instead of how government services improve or saved money, you have a chance of speaking to wether government data makes things better.”
The public knowledge gap regarding this connection is one of the most important points that proponents, advocates, journalists and publishers who wish to see funding for open data initiatives be maintained or Freedom of Information Act reforms pass.
“I think a key implication of the findings is that – if advocates of government data initiatives hope that data will improve people’s views about government’s efficacy – efforts by intermediaries or governments to tie the open data/open government to the government’s collection of data may be worthwhile,” said Horrigan. “Such public awareness efforts might introduce a new “mental model” for the public about what these initiatives are all about. Right now, at least as the data for this report suggests, people do not have a clear sense of government data initiatives. And that means the context for how they think about them has a lot to do with their baseline level of trust in the government – particularly the federal government.”
Horrigan suggested thinking about this using a metaphor familiar to anyone who’s attended a middle school dance.
“Because people do engage with the government online, just through services, it’s like getting them on a big dance floor,” he suggested. “They’re on the floor, where you want them, but they’re on the other part of it. They don’t know that there’s another part of the dance that they’d like to see or be drawn to that they’d want to be in. There’s an opportunity to draw them. The good news that they’re on the dance floor, the bad news is they don’t know about all of it. Someone might want to go over and talk to them an explain that if you go over here you might have a better experience.”
Following are 13 more key insights about the public’s views regarding the Internet, open data and government. For more, make sure to read the full report on open government data, which is full of useful discussion of its findings.
One additional worth noting before you dive in: this survey is representative of American adults, not just the attitudes of people who are online. “The Americans Trends Panel was recruited to be nationally representative, and is weighted in such a way (as nearly all surveys are) to ensure responses reflect the general population,” said Horrigan. “The overall rate of internet use is a bit higher than we typically record, but within the margin of error. So we are comfortable that the sample is representative of the general population.”
Growing number of Americans adults are using the Internet to get information and data
While Pew cautions that the questions posed in this survey are different from another conducted in 2010, the trend is clear: the way citizens communicate with government now includes the Internet, and the way government communicates with citizens increasingly includes digital channels. That use now includes getting information or data about federal, state and local government.
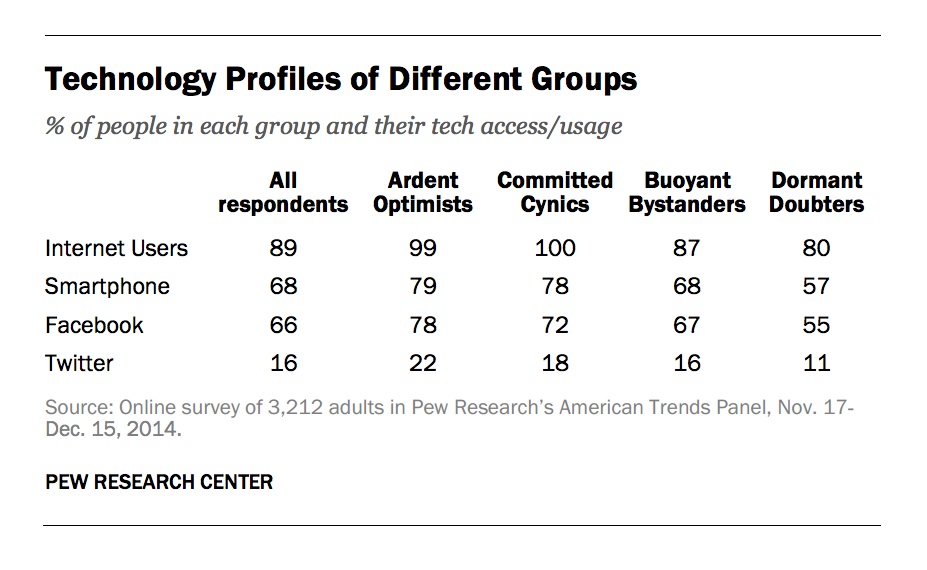
College-educated Americans and millennials are more hopeful about open data releases
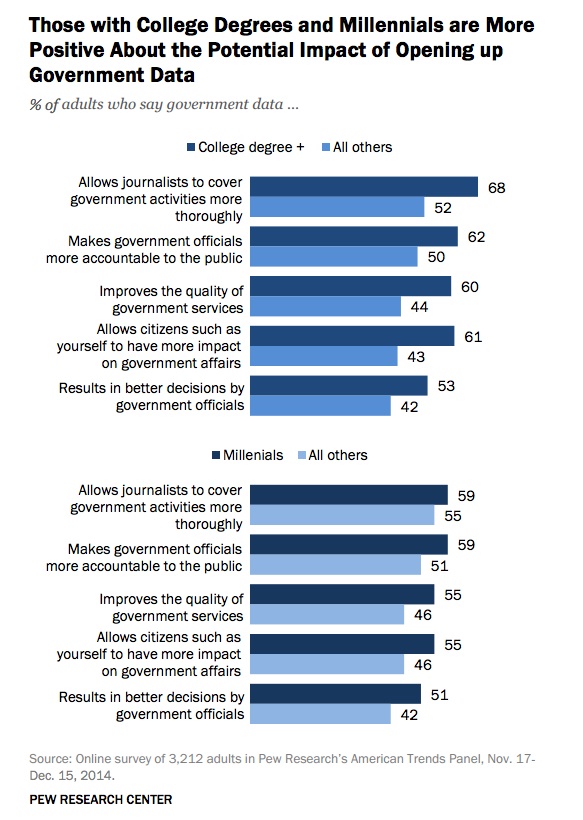
Despite disparities in trust and belief in outcomes, there is no difference in online activities between members of political parties
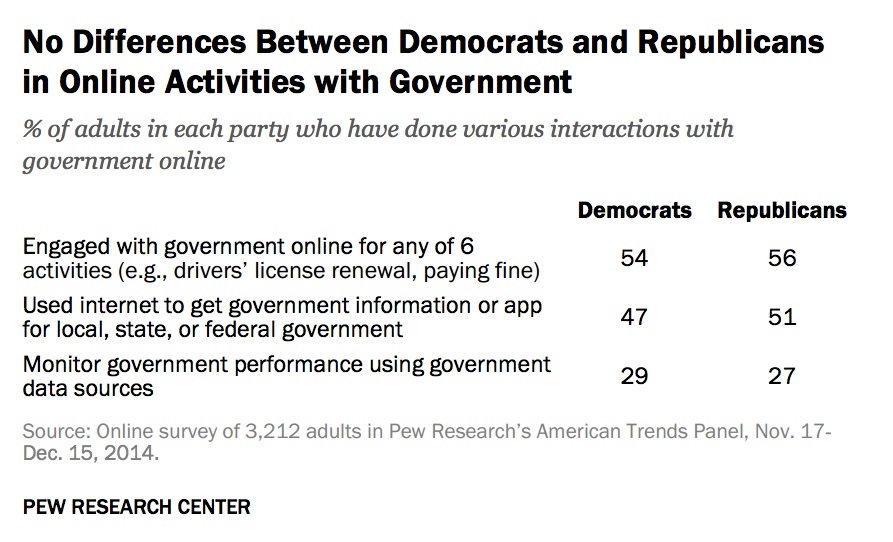
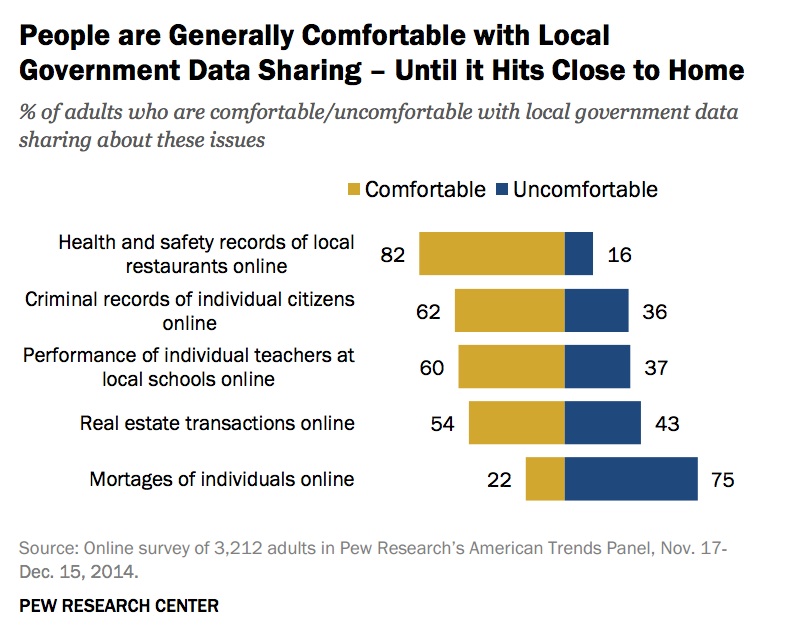
Wealthier Americans are comfortable with open data about real estate transactions but not individual mortgages
This attitude is generally true across all income levels.
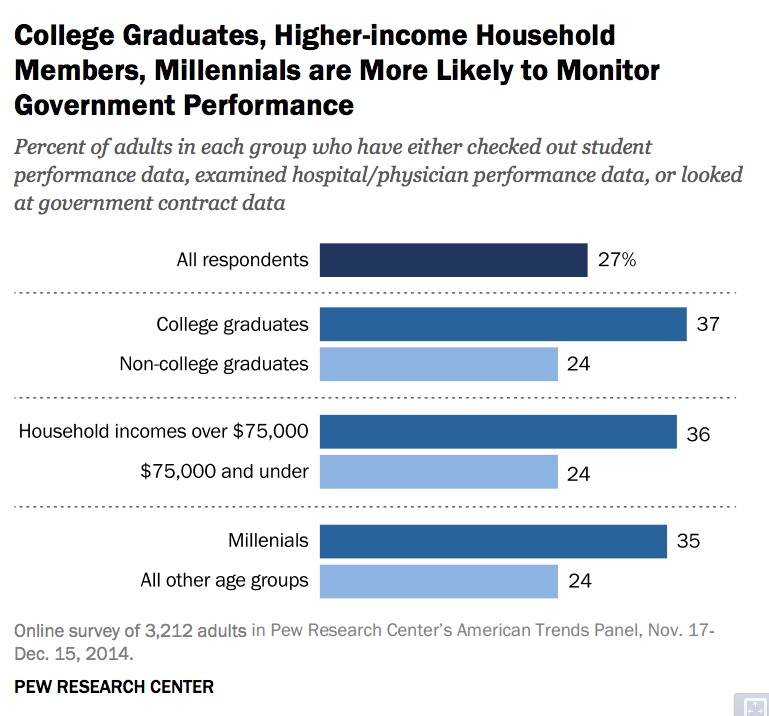
College graduates, millennials and higher-income adults are more likely to use data to monitor government performance
About a third of college grads, young people and wealthy Americans have checked out performance data or government contracting data, or about 50% more than other age groups, lower income or non-college grads.
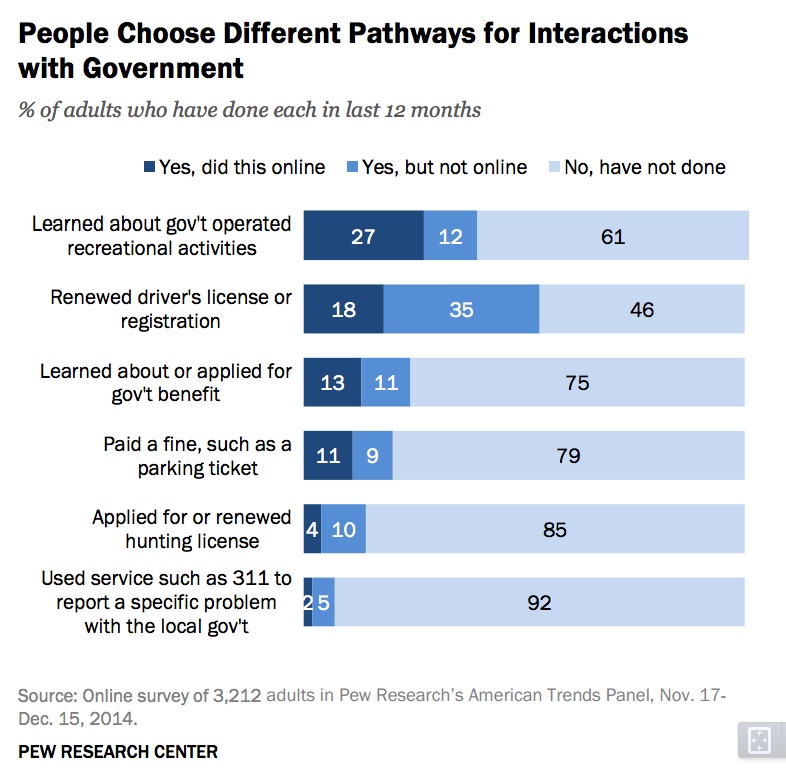
The ways American adults interact with government services and data digitally are expanding
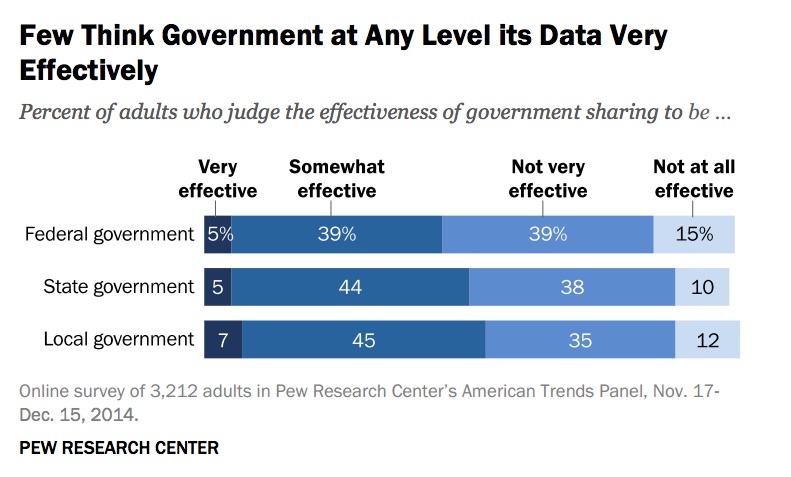
But very few American adults think government data sharing is currently very effective:
A small minority of Americans, however, have a great deal of trust in federal government at all:
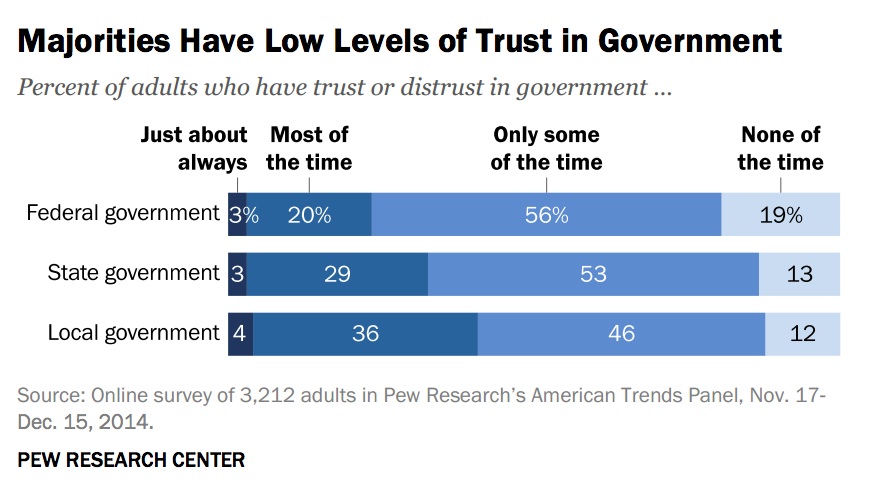
In fact, increasing individual use of data isn’t necessarily correlated with belief in positive outcomes:
Pew grouped the 3,212 respondents into four quadrants, seen below, with a vertical axis ranging from optimism to skepticism and a horizontal axis that described use. Notably, more use of data doesn’t correlate to more belief in positive outcomes.
“In my mind, you have to get to the part of the story where you show government ran better as a result,” said Horrigan. “You have to get to a position where these stories are being told. Then, at least, while you’re opening up new possibilities for cynicism or skepticism, you’re at least focused on the data as opposed to trust in government.”
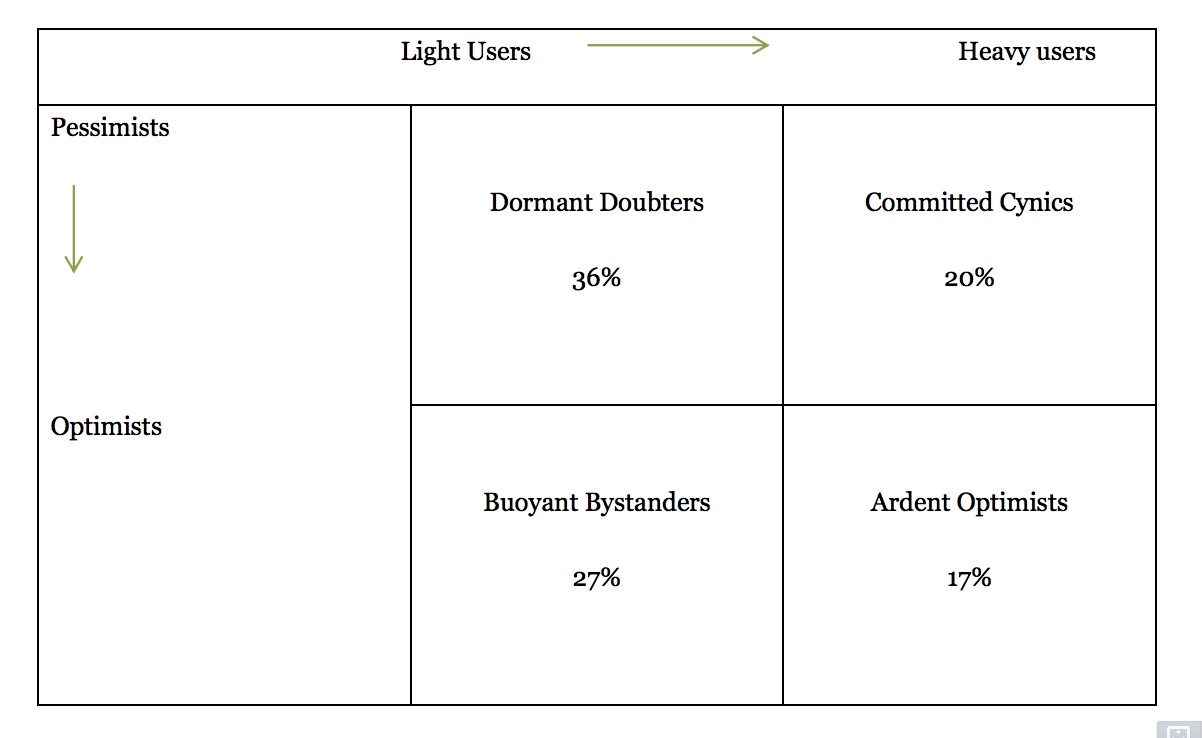

Instead…
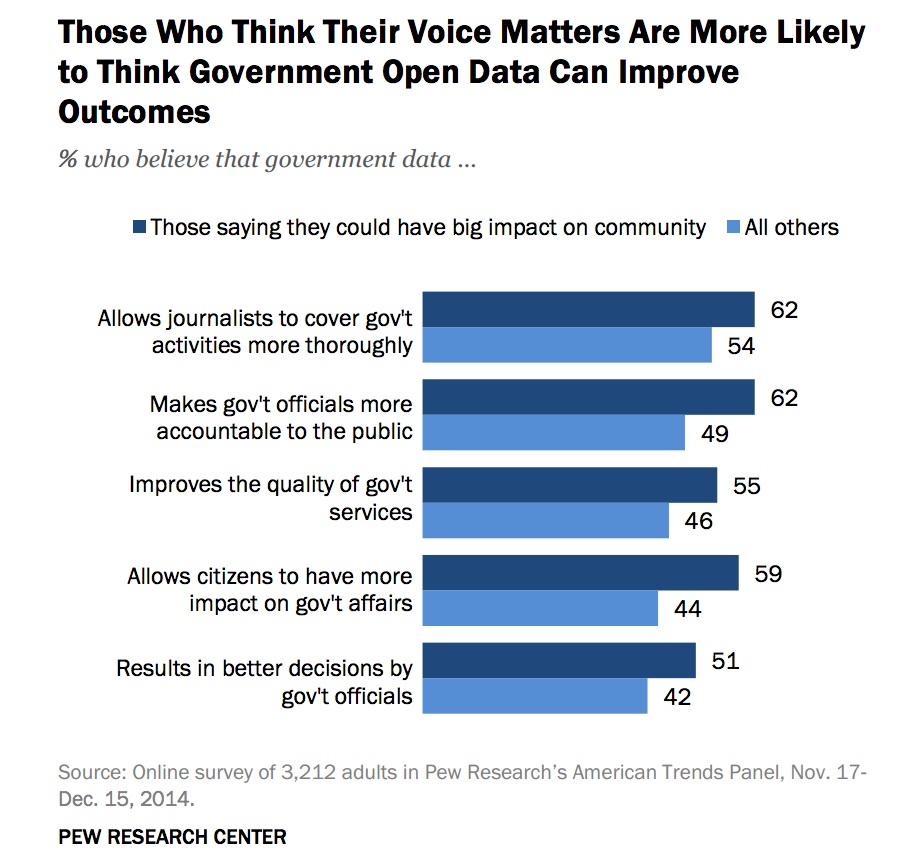
Belief in positive outcomes from the release of open data is correlated with a belief that your voice matters in this republic:
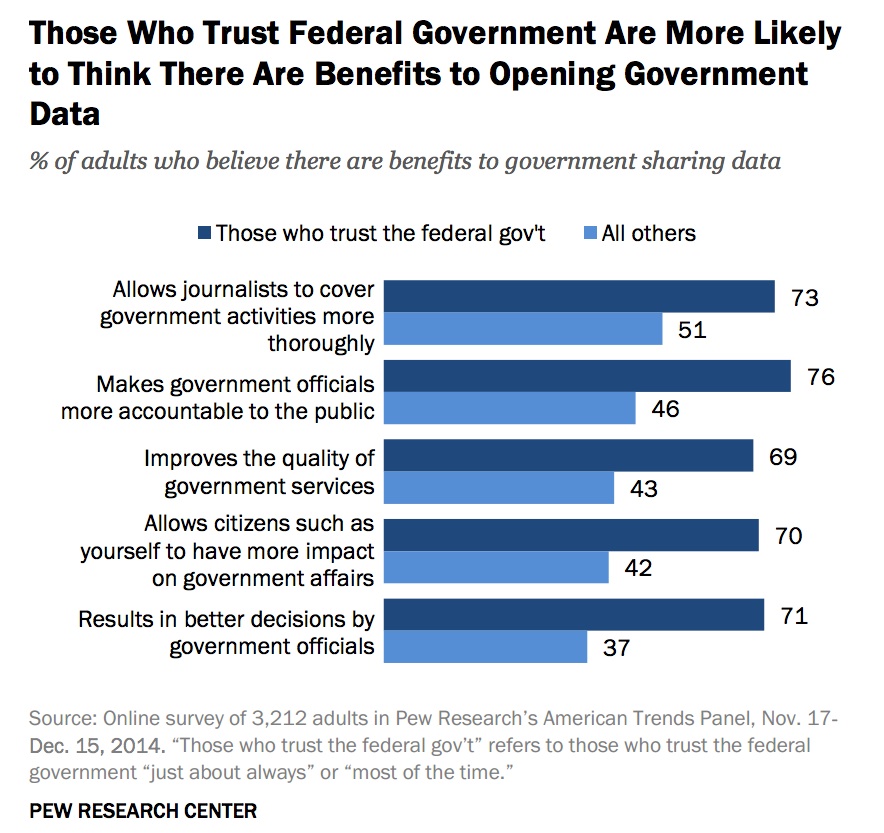
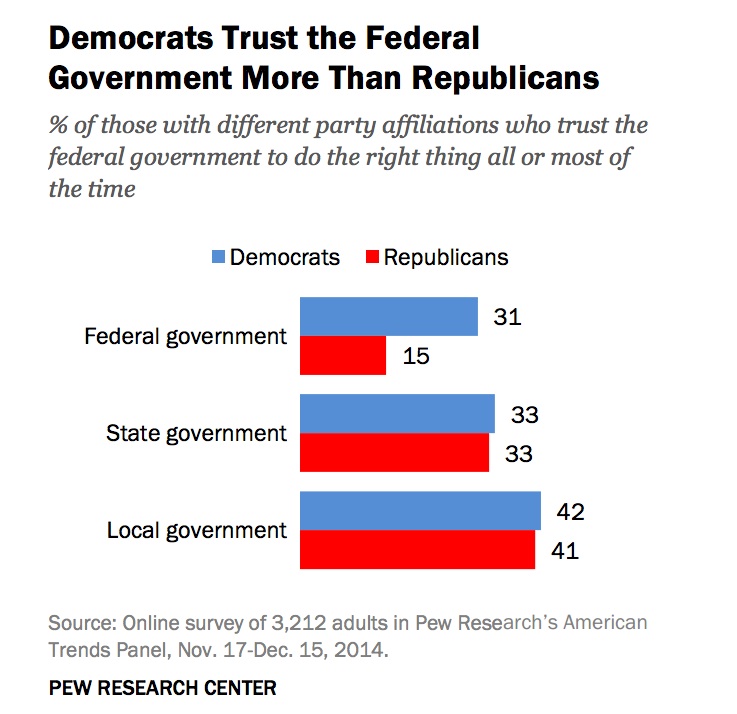
If you trust the federal government, you’re more likely to see the benefit in open data:
But belief in positive outcomes from the release of open data is related to political party affiliation:
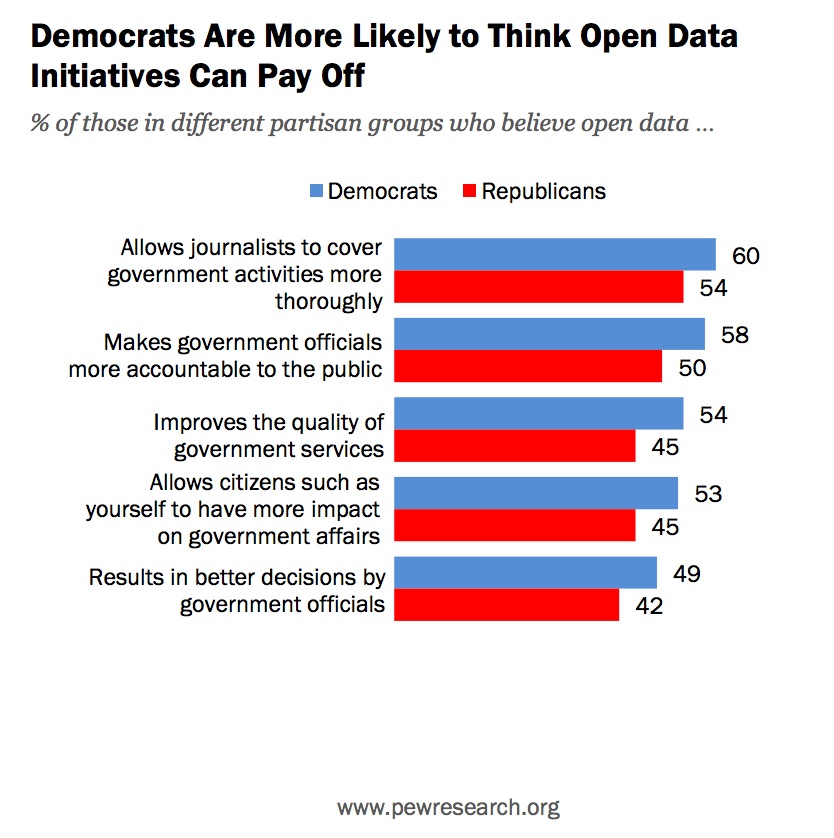
Put simply, Democrats trust the federal government more, and that relates to how people feel about open data released by that government.
Political party has an impact upon the view of open data in the federal government
One challenge is that if President Barack Obama says “open data” again, he may further associate the release of government data with Democratic policies, despite bipartisan support for open government data in Congress. If a Republican is elected President in November 2016, however, this particular attitude may well shift.
“That’s definitely the historic pattern, tracked over time, dating to 1958,” said Horrigan, citing a Pew study. “If if holds and a Republican wins the White House, you’d expect it to flip. Let’s say that we get a Republican president and he continues some of these initiatives to make government perform better, which I expect to be the case. The Bush administration invested in e-government, and used the tools available to them at the time. The Obama administration picked it up, used the new tools available, and got better. President [X] could say this stuff works.”

The unresolved question that we won’t know the answer to until well into 2017, if then, is whether today’s era of hyper-partisanship will change this historic pattern.
There’s bipartisan agreement on the need to use government data better in government. Democratss want to improve efficiency and effectiveness, Republicans want to do the same, but often in the context of demonstrating that programs or policies are ineffective and thereby shrink government. If the country can rise about partisan politics to innovate government, awareness of the utility of releases will grow, along with support for open data will grow.
“Many Americans are not much attuned to government data initiatives, which is why they think about them (in the attitudinal questions) through the lens of whether they trust government,” said Horrigan. “Even the positive part of the attitudinal questions (i.e., the data initiatives can improve accountability) has a dollop of concern, in that even the positive findings can be seen as people saying: ‘These government data initiatives might be good because they will shine more light on government – which really needs it because government doesn’t perform well enough.’ That is an opportunity of course – especially for intermediaries that might, through use of data, help the public understand how/whether government is being accountable to citizens.”
That opportunity is cause for hope.
“Whether it is ‘traditional’ online access for doing transactions/info searches with respect to government, or using mobile apps that rely on government data, people engage with government online, “said Horrigan. “That creates the opportunity for advocates of government data initiatives to draw citizens further down the path of understanding (and perhaps better appreciating) the possible impacts of such initiatives.”
DC city government issues executive order on open data, FOIA portal and chief data officer
Today, the District of Columbia launched a new online service for Freedom of Information Act requests and Mayor Vincent Gray issued a transparency, open government and open data directive. DC city government has come under harsh criticism from the ACLU for its record on FOIA and transparency and has a spate of recent corruption scandals, albeit not one that appears to be worse than other major American cities.
“This new online FOIA system is a key part of our strategy to improve government transparency and accountability,” said Mayor Gray, in a statement. “In addition, the executive order I am issuing today sends an important message to District government agencies and the public: Everyone wins when we make it easier for the public to understand the workings of the District government. I also look forward to seeing the exciting applications I hope the District’s technology community will develop with the government data we will be putting online.”
Here’s what Mayor Gray has instructed DC government to do:
1) Within 30 days from today, the DC chief technology officer (currently Rob Mancini) must create “a common Web portal” that “will serve as the source for District-wide and agency activities related to this Transparency and Open Data Directive.” Translation: OCTO must create a new website that aggregates information related to this directive.
2) OCTO will publish technical standards for open data by November 1, 2014. DC government could refer to the Sunlight Foundation’s Open Data Guidelines as a useful reference, or the canonical 8 principles of Open Government Data.
3) Within 120 days from today, the DC City Administrator and each deputy mayor must identify at least 3 new high-value datasets to publish to the DC Data Catalog that are either not currently available or not available in an exportable format.
4) Starting on October 1, 2014, and continuing annually, each DC agency will develop and publish an “Open Government Report” that will “describe how the agency has or will enhance and develop transparency, public participation, and collaboration. Each agency shall include in its open government report a description of the information (including data) that will be made available to the public, formats in which information and data will be made.”
Translation: city agencies will report on how they’re doing complying with this mandate. Hopefully, the DC Office of Open Government will be an effective ombudsman on that progress, along with directly engaging on Freedom of Information Act disputes and processes, and will do more public engagement around open government or open data than @OCTONEWS has to date.
Unfortunately, and not a little bit ironically, the directive was published online as a scanned-in PDF that is neither searchable nor accessible to the blind, itself embodying the way not to release text online in the 21st century. Below, I have summarized the main deliverables mandated in the directive and converted the images to plain text. Following the order is criticism from open government advocate, civic hacker, and DC resident Josh Tauberer.
GOVERNMENT OF THE DISTRICT OF COLUMBIA
ADMINISTRATIVE ISSUANCE SYSTEM
Mayor’s Order 2014-170
July 21, 2014
SUBJECT: Transparency, Open Government and Open Data Directive
ORIGINATING AGENCY: Office of the Mayor
By virtue of the authority vested in me as Mayor of the District of Columbia by section 422(2) and (11) of the District of Columbia Home Rule Act, approved December 24, 1973, 87 Stat. 790, Pub. L. No. 93-198, D.C. Official Code § 1-204.22(2) and (11) (2012 Repl.), and section 206 of the District of Columbia Freedom of Information Act, effective March 25, 1977, D.C. Law 1-96, D.C. Official Code § 2-536 (2012 Repl.), it is hereby ORDERED that:
SECTION 1: Introduction.
a. Background. The District of Columbia government (“District”) is committed to creating an unprecedented level of openness in government. Agency heads will work together and with the public to ensure public trust, and an open and effective government by establishing a system of transparency, public participation, collaboration, and accountability that increases the public’s confidence in their government. The goal of this directive is to provide a tool for prescribing and institutionalizing change within all departments and agencies.
The District has been a leader in government transparency and open data policy in the United States. In 2001, the Freedom of Information Act was amended to require that certain public records be published online. Since 2006, the District has been making data publicly available on the Internet. In January 2011, Mayor’s Memorandum 2011-1, entitled Transparency and Open Government Policy, was issued, recognizing that the District government needed to continue to proactively provide information to citizens, and thereby reduce the need for information requests. This directive implements Mayor’s Memorandum 2011-1, to require District government departments and agencies to take the following
steps to achieve the goal of creating a more transparent and open government:
b. Definitions.
- “Chief Data Officer” (“CDO”) means the Chief Technology Officer or a Chief Data Officer designated by the Chief Technology Officer.
- “Data” means statistical, or factual, quantitative, or qualitative information that are regularly maintained or created by or on behalf of a District agency, and controlled by such agency in structured formats, including statistical or factual information about image files and geographic information system data.
- “Dataset” means a named collection of related records, with the collection containing data organized or formatted in a specific or prescribed way, often in tabular form.
- “Open Government Coordinator” means agency personnel designated by an agency head, in coordination with the Office of the Chief Technology Officer (“OCTO”) or the CDO as appropriate, to ensure that the information and data required to be published online is published and updated as required by this Order.
- “Protected data” means (i) any dataset or portion thereof to which an agency may deny access pursuant to the District of Columbia Freedom of Information Act, effective March 25, 1977 (D.C. Law 1-96; D.C. Official Code § 2-531 et seq.)(“FOIA”), or any other law or rule or regulation; (ii) any dataset that contains a significant amount of data to which an agency may deny access pursuant to FOIA or any other law or rule or regulation promulgated thereunder, if the removal of such protected data from the dataset would impose an undue financial or administrative burden on the agency; or (iii) any data which, if disclosed on the District of Columbia Data Catalog, could raise privacy, confidentiality or security concerns or jeopardize or have the potential to jeopardize public health, safety or welfare.
C. Scope.
a. The requirements of this Order shall be applied to any District of Columbia department, office, administrative unit, commission, board, advisory committee or other division of the District government (“agency”), including the records of third party agency contractors that create or acquire information, records, or data on behalf of a District agency.
b. Any agency that is not subject to the jurisdiction of the Mayor under the Freedom of Information Act or any other law is strongly encouraged to comply with the requirements of this Order.
SECTION 2: Transparency and Open Government Policy.
a. Publish Government Information Online. To increase accountability and transparency, promote informed public participation, and create economic development opportunities, each District agency shall expand access to information by making it proactively available online, and when practicable, in an open format that can be retrieved, downloaded, indexed, sorted, searched, and reused by commonly used Web search applications and commonly used software to facilitate access to and reuse of information. Examples of open format include HTML, XML, CSV, JSON, RDF or XHTML. The Freedom of Information Act creates a presumption in favor of openness and publication (to the extent permitted by law and subject to valid privacy, confidentiality, security, or other restrictions).
b. Open Government Web Portal: Within 30 days from the date of this Order, the Chief Technology Officer shall establish a common web portal that will serve as the source for District-wide and agency activities related to this Transparency and Open Data Directive. The Chief Technology Officer, in his or her discretion, may build upon an existing web portal, or may establish a new portal. Each agency shall be responsible for ensuring that the information required to be published online is accessible from the agency’s designated Open Government and FOIA webpage. The required information shall include, but is not limited to, where applicable:
- Means for the public to submit and track Freedom of Information Act requests online;
- The information required to be made public under this Directive and D.C. Official Code § 2-536, including links to:
A. Employee salary information;
B. Administrative staff manuals and instructions that affect the public;
C. Final opinions and orders made in the adjudication of cases;
D. Statements of policy, interpretations of policy, and rules adopted by the agency;
E. Correspondence and other materials relating to agency regulatory, supervisory or enforcement responsibilities in which the rights of the public are determined;
F. Information dealing with the receipt or expenditure of public or other funds;
G. Budget information;
H. Minutes of public meetings;
I. Absentee real property owners and their agent’s names and mailing addresses;
J. Pending and authorized building permits;
K. Frequently requested public records; and
L. An index to the records referred to in this section; - Freedom of Information Act reports;
- An organizational chart or statement of the agency’s major components;
- Links to high-value datasets (as defined in section 3(a)(4);
- Public Meeting Notices and minutes required to be published under the Open Meetings Act and Freedom of Information Act; and
- A mechanism for the public to submit feedback on the agency’s Open Government Report or other agency actions.
c. Open Government Report. To institutionalize a culture of transparent and open government, accountability, and to expand opportunities for resident participation and collaboration, beginning October 1, 2014, and each year thereafter, each agency shall develop and publish an Open Government Report that will describe how the agency has or will enhance and develop transparency, public participation, and collaboration. Each agency shall include in its open government report a description of the information (including data) that will be made available to the public, formats in which information and data will be made available, a schedule for making the information available, the dates for which information and datasets will be updated, and contact information for agency Open Government Coordinators. The Open Government Report shall address the following topics, and be transmitted to the Mayor and Director of the Office of Open Government:
- Transparency: The Open Government Report shall reference statutes, regulations, policies, legislative records, budget information, geographic data, crime statistics, public health statistics, and other public records and data, and describe steps each agency has taken or will take to:A. Meet its legal information dissemination obligations under Freedom of Information Act and Open Meetings Act;
B. Create more access to information and opportunities for public participation; and
C. Conduct its work more openly and publish its information online, including a plan for how each board and commission subject to the Open Meetings Act will ensure that all of its meetings are, where practicable, webcast live on the Internet. - Participation: To create more informed and effective policies, each agency shall enhance and expand opportunities for the public to participate throughout agency decision-making processes. The Open Government Report will include descriptions of or plans to provide:A. Online access to proposed rules and regulations;
B. Online access to information and resources to keep the public properly informed (such as frequently asked questions, contact information of city officials’ and departments, and other supportive content);
C. Opportunities for the public to comment through the Web on any proposed rule, ordinance, or other regulation;
D. Methods of identifying stakeholders and other affected parties and inviting their participation;
E. Proposed changes to internal management and administrative policies to improve participation;
F. Links to appropriate websites where the public can engage in the District government’s existing participatory processes;
G. Proposals for new feedback mechanisms, including innovative tools and practices that create new and more accessible methods for public participation; and
H. A plan that provides a timetable for ensuring that all meetings of boardsand commissions that are subject to the Open Meetings Act are webcast live and archived on the Internet. - Collaboration: The Open Government Report will describe steps the agency will take or has taken to enhance and expand its practices to further cooperation among departments, other governmental agencies, the public, and non-profit and private entities in fulfilling its obligations. The Report will include specific details about:A. Proposed changes to internal management and administrative policies to improve collaboration;
B. Proposals to use technology platforms to improve collaboration among District employees and the public;
C. Descriptions of and links to appropriate websites where the public can learn about existing collaboration efforts; and
D. Innovative methods, such as prizes and competitions, to obtain ideas from and to increase collaboration with those in the private sector, non-profit, and academic communities.
SECTION 3: Open Data Policy.
a. Agency Requirements.
- Each agency shall, in collaboration with the Chief Data Officer and OCTO, make available through the online District of Columbia Data Catalog all appropriate datasets, associated extensible metadata, and associated documented agency business processes under the agency’s control. Each agency, in collaboration with OCTO, shall determine the frequency for updates to a dataset, and the mechanism to be utilized. To the extent possible, datasets shall be updated through an automated process to limit the additional burden on agency resources. The publication of an agency’s datasets shall exclude protected data.
- Datasets under paragraph (4) shall be made available in accordance with technical standards published by OCTO not later than November 1, 2014 that ensure that data is published in a format that is machine readable, and fully accessible to the broadest range of users, for varying purposes. Datasets shall be made available to the public on an open license basis. An open license on a dataset signifies there are no restrictions on copying, publishing, further distributing, modifying or using the data for a non-commercial or commercial purpose.
- For the purposes of identifying datasets for inclusion on the District of Columbia Data Catalog, each agency shall consider whether the information embodied in the dataset is (i) reliable and accurate; (ii) frequently the subject of a written request for public records of the type that a public body is required to make available for inspection or copying under FOIA; (iii) increases agency accountability, efficiency, responsiveness or delivery of services; (iv) improves public knowledge of the agency and its operations; (v) furthers the mission of the agency; or (vi) creates economic opportunity.
- Within 120 days of the date of this Order, the City Administrator and each Deputy Mayor shall, collaborating with their cluster agencies, and OCTO, identify at least 3 new high-value datasets to publish to the Data Catalog, in accordance with OCTO’s open data standards. The identified high-value datasets will not be currently available, or not available in an exportable format. For the purposes of this section, “high-value dataset” includes agency outcome data, agency caseload data, data reported to the federal government outcome data, agency caseload data, data reported to the federal government by the agency, agency data reported as part of the performance measurement process, and any data that is tracked by the agency that is not protected data.
b. Chief Data Officer.
- The Chief Technology Officer shall designate a Chief Data Officer (“CDO”) for the District of Columbia to coordinate implementation, compliance and expansion of the District’s Open Data Program, to facilitate the sharing of information between departments and agencies, and to coordinate initiatives to improve decision making and management through data analysis. The Chief improve decision making and management through data analysis. The Chief Data Officer shall report to the Chief Technology Officer.
- The Chief Data Officer shall:
A. Identify points of contact, which may include agency open government coordinators within departments, on data related issues who will be responsible for leading intra-departmental open data initiatives;
B. Emphasize the culture behind open data and the benefits to ensure that opportunities to increase efficiency through open data practices can be obtained from those with the most direct expertise;
C. Work together with District agencies to develop a methodology and framework that supports the collection, or creation of data in a way that assists in downstream data processing and open data distribution activities;
D. Identify and overcome challenges with agency proprietary business systems; create and/or leverage opportunities through procurement or other means to upgrade legacy systems to one of an open data architecture; and
E. Function as a data ombudsman for the public, fielding public feedback and ensuring the policy is included into a long-term data strategy.
c. District of Columbia Open Data Catalog.
- A single web portal, or integrated set of websites, shall be established and maintained by or on behalf of the District of Columbia. The Chief Data maintained by or on behalf of the District of Columbia. The Chief Data Officer, in collaboration with OCTO, may build upon previous open data initiatives, or may establish a new portal for managing and delivering open data benefits to constituents.
- Any dataset made accessible on the District of Columbia Data Catalog shall use an open format that permits automated processing of such data in a form that can be retrieved via an open application programming interface (API), downloaded, indexed, searched and reused by commonly used web search applications and software; (ii) use appropriate technology to notify the public of updates to the data; and (iii) be accessible to external search capabilities.
- OCTO shall (i) post on the portal a list of all datasets available on such portal; and (ii) establish and maintain on the portal an online forum to solicit feedback from the public and to encourage public discussion on open data policies and dataset availability.
d. Open Data Legal Policy.
- The District of Columbia Data Catalog and all public data contained on such portal shall be subject to Terms of Use developed by OCTO. Such Terms of Use shall be posted by OCTO in a conspicuous place on the District ofColumbia Data Catalog.
- Public data made available on the District of Columbia Data Catalog shall be provided as a public service, on an “as is” basis. Although the District will strive to ensure that such public data are accurate, the District shall make no warranty, representation or guaranty of any type as to the content, accuracy, timeliness, completeness or fitness for any particular purpose or use of any public data provided on such portal; nor shall any such warranty be implied, including, without limitation, the implied warranties of merchantability and fitness for a particular purpose. The District shall assume no liability for any other act identified in any disclaimer of liability or indemnification provision or any other provision set forth in the Terms of Use required under subsection (d)(1) of this section.
- The District shall reserve the right to discontinue availability of content on the District of Columbia Data Catalog at any time and for any reason. If a dataset is made accessible by an agency on the District of Columbia Data Catalog and such agency is notified or otherwise learns that any dataset or portion thereof posted on the Data Catalog is factually inaccurate or misleading or is protected data, the agency shall, as appropriate, promptly correct or remove, or cause to be corrected or removed, such data from the Data Catalog and shall so inform the Chief Data Officer.
- Nothing in this Order shall be deemed to prohibit OCTO or any agency or any third party that establishes or maintains the District of Columbia Data Catalog on behalf of the District from adopting or implementing measures necessary or appropriate to (1) ensure access to public datasets housed on the Data Catalog; (ii) protect the Data Catalog from unlawful use or from attempts to impair or damage the use of the portal; (iii) analyze the types of public data on the Data Catalog being used by the public in order to improve service delivery or for any other lawful purpose; (iv) terminate any and all display, distribution or other use of any or all of the public data provided on the Data Catalog for violation of any of the Terms of Use posted on the Data Catalog pursuant to subsection (d)(1) of this section; or (v) require a third party providing the District’s public data (or applications based on public data) to the public to explicitly identify the source and version of the public dataset, and describe any modifications made to the public dataset.
- Nothing in this Order shall be construed to create a private right of action to enforce any provision of this Order. Failure to comply with any provision of this Order shall not result in any liability to the District, including, but not limited to, OCTO or any agency or third party that establishes or maintains on behalf of the District the Open Data Services Portal required under this Order.
Section 4. Open Government Advisory Group.
a. The Mayor shall convene an Open Government Advisory Group to be chaired and convened by the Mayor’s designee, CDO, and the Director of the Office of Open Government within the Board of Ethics and Government Accountability.
b. The Open Government Advisory Group shall:
- Evaluate the District’s progress towards meeting the requirements of this Order and make specific recommendations for improvement; and
- Assist the Mayor and CDO in creating policy establishing specific criteria for agency identification of protected data in accordance with FOIA, maintenance of existing data, and the creation of data in open formats.
c. The CDO shall publish the evaluation and recommendations on the Open Government Web Portal or create an Open Government Dashboard that will provide the public with both graphic and narrative evaluation information.
Section 5: EFFECTIVE DATE:
This Order shall be effective immediately.
VINCENT C. GRAY
MAYOR
ATTEST:
CYNTHIA BR CIS-SMITH
SECRETARY OF THE DISTRICT OF COLUMBIA
After the order was published online, GovTrack.us founder Josh Tauberer issued a series of critical tweets and extended his thoughts into a blog post, holding that DC city government adopted the mistakes made by the White House:
There is a strong American tradition — or at least a core American value — that the government does not get in the way of the dissemination of ideas. We don’t always live up to that ideal, but we strive for it. Access to information about the government that comes with restrictions on what we can say when we use it (e.g. attribution & explanation), a waiver of rights or a commitment to indemnify, etc. are all an anathema to accountability and transparency and respect for the public.
.@mayorvincegray‘s new open gov directive is pub’d in a non-searchable, scanned-image PDF. Do they get it?? http://t.co/rQoQ6JGZyj
— Joshua Tauberer (@JoshData) July 21, 2014
The DC open gov directive is modeled after the T/P/C definition of #opengov from Obama’s 2009 directive. Meh. “Collaboration” was a #fail.
— Joshua Tauberer (@JoshData) July 21, 2014
.@mayorvincegray‘s DC #opengov directive also f’ed up “open licensing.” Am kind of pissed at @WhiteHouseOSTP for starting this confusion.
— Joshua Tauberer (@JoshData) July 21, 2014
OCTO is instructed to create a Terms of Use to govern public use of DC gov data. Another major #fail for @mayorvincegray.
— Joshua Tauberer (@JoshData) July 21, 2014
When the new DC data catalog terms go up, I will encourage folks to FOIA for the same data to avoid agreeing to gov’s terms.
— Joshua Tauberer (@JoshData) July 21, 2014
Imagine if records made available under FOIA came with an EULA. No thanks!
— Joshua Tauberer (@JoshData) July 21, 2014
U.S. CIO Steven VanRoekel on the risks and potential of open data and digital government
Last year, I conducted an in-depth interview with United States chief information officer Steven VanRoekel in his office in the Eisenhower Executive Office Building, overlooking the White House. I was there to talk about the historic open data executive order that President Obama had signed in May 2013.  On this visit, I couldn’t help but notice that VanRoekel has a Star Wars clock in his office. The Force is strong here. The US CIO also had a lot of other consumer technology around his workspace: a MacBook and Windows laptop and dock, dual monitors, iPad, a teleconferencing system integrated with a desktop PC, and an iPhone, which recently became securely permissible on in the White House IT system in a “bring your own device” pilot. The interview that follows is slightly dated, in certain respects, but still offers significant insight into how the nation’s top IT executive is thinking about digital government, open data and more. It has also been lightly edited, primarily removing the long-winded questions of the interviewer.
On this visit, I couldn’t help but notice that VanRoekel has a Star Wars clock in his office. The Force is strong here. The US CIO also had a lot of other consumer technology around his workspace: a MacBook and Windows laptop and dock, dual monitors, iPad, a teleconferencing system integrated with a desktop PC, and an iPhone, which recently became securely permissible on in the White House IT system in a “bring your own device” pilot. The interview that follows is slightly dated, in certain respects, but still offers significant insight into how the nation’s top IT executive is thinking about digital government, open data and more. It has also been lightly edited, primarily removing the long-winded questions of the interviewer.
We’re at the one year mark of the Digital Government Strategy. Where do we stand with hitting the metrics in the strategy? Why did it take until now to get this out?
VanRoekel: The strategy calls for the launch of the policy itself. Throughout the year, the policy was a framework for a 12 month set of deliverables of different aspects, from the work we’re doing in mobile, from ‘bring your own device,’ to security baselines and mobile device management platforms. Not only streamlining procurement, streamlining app development in government. Managing those devices securely to thinking about the way we do customer service and the way we think about the power of data and how it plays into all of this. It’s been part of that process for about the year we’ve been working on it. Of course, we thought through these principles and have been working on data-related aspects for longer. The digital strategy policy was the framework for us to catalyze and accelerate that, and over the course of the year, the stuff that’s been going on behind the scenes has largely been working with agencies on building some of this capability around open data. You’re going to see some things happening very soon on the release of some of this capability. Second, standing up the Presidential Innovation Fellows program and then putting specific ‘PIFs’ into certain targeted agencies to fast track their opening of data — that’s going to extend into Wave Two. You’re going to see that continuing to happen, where we just take these principles and just kind of ‘rinse and repeat’ in government. Third, we’re working with a small set of the community to build tools to make it easy for agencies to implement these guidelines. So if there’s an agency that doesn’t know how to create a JSON file, that tool is on Github. You can see that on Project Open Data .
How involved has the president been in this executive order? It’s his name, his words are in there — how much have you and U.S. chief technology officer Todd Park talked with the president about this?
VanRoekel: Ever since about last summer, we’ve been talking to the president about open data, specifically. I think there’s lots of examples where we’ve had conversations on the periphery, and he’s met with a lot of tech leaders and others around the country that in many, many cases have either built their business or are relying upon some government service or data stream. We’re seeing that culminating into the mindset of what we do as a factor of economic growth. His thoughts are ‘how do we unlock this national resource?’ We’re sitting on this treasure trove – how do we unleash it into the developer community, so that these app developers can build these different solutions?’ He’s definitely inspired – he wrote that cover memo to the digital strategy last May – and then we’ve had all of these different meetings, across the course of the year, and now it culminates into this executive order, where we’re working to catalyze these agencies and get them to pay attention and follow up.
We’ve been down this road before, in some respects, with the Open Government Directive in 2009, with former US CIO Vivek Kundra putting forward claims of positive outcomes from releasing data. Yet, what have we learned over the past four years? What makes this different? Where’s the “how,” in terms of implementing this?
VanRoekel: The original launch of data.gov was, I think, a way of really shocking the system, and getting people to pay attention to and notice that there was an important resource we’re sitting on called data. Prior to data.gov, and prior to the work of this administration, the daily approach to data was very ad hoc. It wasn’t taken as data, it was just an output or a piece of a broader mix. That’s why you get so much disparity in the approach to the way we manage data. You get the paper-driven processes that are still very prevalent, where someone will send a paper document, and someone will sign it, and scan it, feed it into a system, and then eventually print it and mail it. It’s crazy what you end up seeing and experiencing inside of government in terms of how these things work. Data.gov was an important first step. The difference now is really around taking this approach to everything that we do. The work that we did with the Open Government Directive back in 2009 was really about taking some high value data sets and putting them up on Data.gov. What you ended up seeing was kind of a ‘bulk upload, bulk download,’ kind of access to the data. Machine-readability and programmability wasn’t taken into account, or the searchability and findability.
Did entrepreneurs or advocates validate these data sets as “high value?” Entrepreneurs have kept buying data from government over the past four years or making Freedom of Information Act requests for data from government or scraping data. They’re not getting that from Data.gov.
VanRoekel: I have no official way of measuring the ‘value’ of the data, other than anecdotal conversations. I do think that the motion of getting people to wake up and think about how they are treating data internally within in an organization – well, there was a convenience factor to that, which basically was that ‘I got to pick what data I release,’ which probably dates from ‘what data I have that’s releasable?’ The different tiers to this executive order and this policy are a huge part of why it’s different. It sets the new default. It basically says, if you are modernizing a system or creating a new system, you can do that in a way that adopts these principles. If you [undertake] the collection, use and dissemination of data, you’ll make those machine-readable and interoperable by default. That doesn’t always mean public, because there are applications that privacy and national security mean we should make public, but those principles still hold, in terms of the way I believe we the ways we build things should evolve on this foundation. For the community that’s getting value outside of the government, this really sets a predictable, consistent course for the government to open up data. Any business decisions are risk-based decisions. You have to assume some level of risk with anything you do.
If there’s too much risk, entrepreneurs won’t do it.
VanRoekel: True. To that end, the work we’ve done in this policy that’s different than before is the way we’re collecting information about the data is being standardized. We’re creating a meta data infrastructure. Data itself doesn’t have to be all described in the same way. We’re not coming up with “one schema to rule them all” across government. The complexity of that would be insurmountable. I don’t think that’s a 21st century approach. That’s probably a last century thinking around to say that if we get one schema, we’re going to get it all done. The meta data approach is to say let’s collect a standard template way of describing – but flexible for future extension – the data that is contained in government. In that description, and in that meta data, tags like “who owns this data” and “how often is the data updated,” information about how to get a hold of people to find out more about descriptions within the data. They will be a part of that description in a way that gives you some level of assurance on how the data is managed. Much of the data we have out there, there’s existing laws on the books to collect the data. Most of it, there’s existing laws, not just a business process. One of the great conversations we’re having with the agencies is that they find greater efficiency in the way they collect data and build solutions based upon these open data principles.
I received a question from David Robinson, regarding open licensing in this policy. Isn’t U.S. government data exempt from copyright?
VanRoekel: Not all government data is exempt from copyright, but those are generally edge cases. The Smithsonian takes pictures of things that are still under copyright, for instance. That’s government data. I sent a note about this announcement to the Secretary of the Smithsonian this morning. I’ve been talking to him about opening up data for some time. The nuance there, about open licenses, is really around the types of systems that create the data, and putting a preference for a non-proprietary format. You can imagine a world in which I give you an XML file, and I give you a Microsoft Excel file. Those are both piece of data. To some extent, the Excel format is machine-readable. You can open it up and look at it internally just the way it is, but do you have to go buy a special piece of software to read the file or not? That kind of denotes the open[ness] and accessibility of the data. In the case of policy, we declare a strong preference towards these non-proprietary formats, so that not only do you get machine-readability but you get the broadest access to the data. It’s less about the content in there – is that’s copyrighted or not — I think most data in government, outside of the realm of confidential or private data, is not copyrighted, so to speak from the standpoint of the license. It’s more about the format, and if there’s a proprietary standard wrapped in the stuff. We have an obligation as a government to pick formats, pick solutions, et cetera that not only have the broadest applicability and accessibility for the public but also create the most opportunity in the broadest sense.
Open data doesn’t come without costs. Is this open data policy an unfunded mandate on all of the agencies, instructing them to put all of the data online they can, to digitize content?
VanRoekel: In the broadest sense, the phrase ‘the new default’ is an important one. It basically says, for enhancements to existing systems or new systems, follow this guideline. If people are making changes, this is in the list of requirements. From a costing perspective, it’s pre-baked into the cost of any enhancement or release. That’s the broad statement. The narrow statement is that there are many agencies out there, increasing every day, that are embracing these retroactive open data approaches, saying that there is value to the outside world, there is lower cost, greater interoperability, there are solutions that can be derived from taking these open data approaches inside of my own organization. That’s what we saw in PIF [Presidential Innovation Fellows] round one, where these agencies adopted the innovations fellows to unlock their data. That’s increasing and expanding in round two, and continuing in the agencies which we thought were high administration priorities, along with others. I think we’re going to continue to see this as a catalyzing element of that phenomenon, where people are going to back and spend the resources on doing this. Just invite any of these leaders to the last twenty minutes of a hackathon, where folks are standing up and showing their solutions that they developed in one day, based on the principles of open data and APIs. They just are overwhelmed about the potential within their own organizations, and they run back and want to do this as fast as they can.
Are you using anything that has ever been developed at a hackathon, personally or professionally?
VanRoekel: We are incorporating code from the “We The People” hackathon, the most recent one. I know Macon Phillips and team are looking at incorporating feature sets they got out of that. An important part of the hackathon, like most conferences you go to, is the time between the sessions. They’re the most important – the relationship building aspect, figuring out how we shape the next set of capabilities or APIs or other things you want to build.
How does this relate to the way that the federal government uses open data internally?
VanRoekel: There are so many examples of government agencies, when faced with a technical problem, will go hire a single monolithic vendor to do a single, monolithic solution – and spend most of the budget on the planning cycle – and you end up with these multi-million dollar, 3-ring binders that ultimately fail because technology has moved on or people have left or laws have moved on five or ten years later, after they started these projects. One of the key components of this is laying foundational stones down to say how are we going to build upon that, to create the apps and solutions of the future. You know, I can swoop in and say “here’s how to do modular contracting in the context of government acquisition” – but unless you say, you’ve got to adopt open data and these principles of API-first, of doing things a different way — smaller, reusable, interoperable pieces – you can really build the phenomenon. These are all elements of that – and the cost savings aspect of it are extraordinary. The risk profile is going to be a lot smaller. Inside government I’m as excited about as outside.
Do you think the federal government will ever be able to move from big data centers and complicated enterprise software to a lightweight, distributed model for mobile services built on APIs?
VanRoekel: I think there is massive potential for things like that across the whole of government. I mean, we’re a big organization. We’re the largest buyer of technology in the world. We have unending opportunities to do things in a more efficient way. I’ve been running this process that I launched last year called Portfolio Stat. It’s all about taking a left to right look, sitting down with agencies. What I’ve always been missing from those is some of these groundbreaking policies that start to paint the picture for what the ideal is, and how to get your job done in a way that’s different than the way you’ve don’t it before, like the notion of continuous improvement. We’ve needed things like the EO to give us those conversation starters to say, here’s the way to do it, see what they are doing over at HHS. “How are you going to bring that kind of discipline into your organization?” I’m sitting down with every deputy secretary and all the C-level executives to have those tough conversations. Fruitful, but good conversations about how we are going to change the way we deliver solutions inside of government. The ideal state that they’ll all hear about is the service-oriented model with centralized, commodity computing that’s mostly cloud-based. Then, how do you provide services out to the periphery of your organization.
You told me in our last interview that you had statutory authority to make things happen. What happens if a federal CIO drags his or her feet and, a year from now, you’re still here and they’re not moving on these policies, from cloud to open data?
VanRoekel: The answer I gave to you last time still holds: it’s about inspire and push. Inspire comes in many factors. One is me coming in and showing them the art of the possible, saying there’s a better way of doing this, getting their customers to show up at the door to say that we want better capabilities and get them inspired to do things, getting their leadership to show up and say we want better things. Push is about budget – how do you manage their budget. There’s aspects of both inspire and push in the way we’ve managed the budget this year. I have the authority to do that.
What’s your best case for adopting an open data strategy and enterprise data inventory, if you’re trying to inspire?
VanRoekel: The bottom line is meet your mission faster and at a much lower cost. Our job is not about technology as an end state – it’s about our mission. We’ve got to get the mission of government done. You’re fostering immigration, you’re protecting public safety, you’re providing better energy guidance, you’re shaping an industry for the country. Open data is a fundamental building block of providing flexibility and reusability into the workplace. It’s what you do to get you to the end state of your mission. I hearken back a lot to the examples we used at the FCC, which was moving from like fourteen websites to one and how we managed that. How do we take workload of a place so that the effort pays for itself in six months and start yielding benefits beyond that? The benefits are long-term. When you build that next enhancement, or that new thing on top of it, you can realize the benefits at lower cost. It’s amazing. I do these TechStat processes, where I sit down with the agencies. They have some project that’s going off the rails. They need help, focus, and some executive oversight. I sit down, usually in a big room of people, and it’s almost gotten to the point where you don’t need to look at the briefing documents ahead of time. You sit down and say, I bet you’re doing it this way – and it’s monolithic, proprietary, probably taking a lot of packaged software and writing a lot of glue code to hold it all together – and you then propose to them the principles of open data and open approaches to doing the solution, and tell them I want to see in the next sixty days some customer-facing, benefit value that’s built on this model. They go off and do that, and they get right back on the tracks and they succeed. Time after time when we do TechStat, that’s the formula and it’s yielded these incredible results. That culture is starting to permeate into how we get stuff done, because they see how it might accomplish their mission if they just turn 45 degrees and try a different approach. If that makes them successful, they will go there every time.
Critiques of open data raise concerns about “discretionary disclosure,” where a government entity releases what it wants, claim credit for embracing open government, and obfuscates the rest of the data. Does this policy change any of the decisions that are being made to delay, redact or not release requested data?
VanRoekel: I think today marks an inflection point that will set a course for the future. It’s not that tomorrow or next month or next year that all government data will just be transformed into open, machine-readable form. It will happen over time. The key here is that we’ve created mechanisms to protect privacy and security of data but built in culture where that which is intended to be public should be made public. Part of what is described in the executive order is the formation of this cross-agency executive group that will define a cross-agency priority goal, that we need to get inventories in from agencies regarding that which they hold that could be made public. We want to know stuff that’s not public today, what could be out there. We’re going to take that in and look at how we can set goals for this year, the next year and the year after that to continue to open up data at a faster pace than we’ve been doing in the past. The modernization act and some of the work around setting goals in government is much more compatible and looks a lot like the private sector. We’re embracing these notions that I’ve really grown to love and respect over the course of my private sector career in government around methodologies. Stay tuned on the capital and what that looks like.
Are you all going to work with the House and Senate on the DATA Act or are statutory issues on oversight still a stumbling block?
VanRoekel: The spirit of the DATA Act, of transparency and openness, are the things we’re doing, and I think are embraced. Some of the tactical aspects of the act were a little off the mark, in terms of getting to the end state that we want to get to. If you look at the FY-14 budget and the work we’ve done on transferring USASpending.gov to Treasury to get it closer to the source of the data, plus a view into how those systems get modernized, how we bring these principles into that mix, that will all be a part of the end state, which is how we track the spending.
Do you ever anticipate the data going into FOIA.gov also going into Data.gov?
VanRoekel: I don’t know. I can’t speculate on that. I’m not close enough to it.
Well, FOIA requests show demand. Do you have any sense of what people are paying for now, in terms of government data?
VanRoekel: I don’t.
Has anybody ever asked, to try to figure that out?
VanRoekel: I think that would be a great thing for you to do.
I appreciate that, but this strikes me as an interesting assessment that you could be doing, in terms of measuring outflows for business intelligence. If someone buys data, it shows that there is value in it. What would it mean if releases reflected that signal?
VanRoekel: You mean preference data that is being purchased?
Right.
VanRoekel: Well, part of this will be building and looking at Data.gov. Some of the stuff coming there is really building community around the data. The number one question Todd Park and I had coming out of the PIF program, at the end of May [2013] was, what if I think there’s data, but I don’t know, who do I contact? An important part of the delivery of this wave and the product coming out as part of this policy is going to be this enhanced Data.gov, that’s our intention to build a much richer community around government data. We want to hear from people. If there are data sources that do hold promise and value, let’s hear about those and see if there are things we can do to get a PIF on structuring it, and get agencies to modernize systems to get it released and open. I know some of the costs are like administrative feeds for printing or finding the data, something that’s related to third parties collecting it and then reselling it. We want to make sure that we’re thoughtful in how we approach that.
How has the experience that you’ve seen everyone have with the first iteration of Data.gov informed the nation’s open data strategy today? What specifically had not been done before that you will be doing now?
VanRoekel: The first Data.gov set us on a cultural path.What it didn’t do was connect you to data the source. What is this data? How often is it updated? Findability and searchability of broad government data wasn’t there. Programmability of the data wasn’t necessarily there. Data.gov, in the future, instead of being a repository for data, a place to upload the data, my intention is that it will become a meta data catalog. It will be the place you go, the one-stop-shop, to find government data, across multiple aspects. The way we’re doing this is through the policy itself, which says that agencies have to go and set up this new page, similar to what is now standard in open government, /open, /developer. In that page, the most important part of that page is a JSON file. That’s what data.gov can go out and crawl, or any developer outside can go out and crawl, to find out when data has been updated, what data is available, in what format. All of the standard meta data that I’ve described earlier will be represented through that JSON file. Data.gov will then become a meta data catalog of all the open data out in government at its source. As a developer, you’d come in, and it you wanted to do a map, for instance, to see what broadband capabilities exist near low-income Americans and then overlay locations of educational institutions, if you wanted to look for a correlation between income and broadband deployment and education, you’d hypothetically be looking for 3 different data sources, from 3 different agencies. You’d be able to find the open data streams, the APIs, to go get that data in one place, and then you’d have a connection back to the mothership to be able to grab it, find out who owns it. We want to still have a center of gravity for data, but make the data itself follow these principles, in terms of discoverability and use. The thing that probably got me most pointed in this direction is the President’s Council of Advisors on Science and Technology (PCAST), which did a report on health IT. Buried on page 60 or something, it had this description of meta data as the linchpin of discoverability of diverse data sources. That’s the approach we’ve taken, much like Google.
5 years from now, what will have changed because of this effort?
VanRoekel: The way we build solutions inside of government is going to change, and the amount of apps and solutions outside of government are going to fundamentally change. You and I now, sitting in our cars, take for granted the GPS signal going to the device on the dash. I think about government. Government is right there with me, every single day, as I’m driving my car, or when I do a Foursquare check-in on my phone. We’ll be bringing government data to citizens where they are, versus making people come to government. It’s been a long time since the mid-80s, when we opened up GPS, but look at where we are today. I think we’ll look back in 10 or 15 years and think about all of the potential we unlocked today.
What data could be like GPS, in terms of their impact on our lives?
VanRoekel: I think health and energy are probably two big ones.
POSTSCRIPT
Since we talked, the Obama administration has followed through on some of the commitments the U.S. CIO described, including relaunching Data.gov and releasing more data. Other goals, like every agency releasing an enterprise data inventory or publishing a /data and /developer page online, have seen mixed compliance, as an audit by the Sunlight Foundation showed in December. The federal government shutdown last fall also scuttled open data access, where certain data types were deemed essential to maintain and others were not. The shutdown also suggested that an “API-first” strategy for open data might be problematic. OMB, where VanRoekel works, has also quietly called for major changes in the DATA Act, which passed the House of Representatives with overwhelming support at the end of last year. A marked up version of the DATA Act obtained by Federal News Radio removes funding for the legislation and language that would require standardized data elements for reporting federal government spending. The news was not received well on Capitol Hill. Sen. Mark Warner, D-Va., the lead sponsor of the DATA Act in the Senate, reaffirmed his commitment to the current version of the bill in statement: “The Obama administration talks a lot about transparency, but these comments reflect a clear attempt to gut the DATA Act. DATA reflects years of bipartisan, bicameral work, and to propose substantial, unproductive changes this late in the game is unacceptable. We look forward to passing the DATA Act, which had near universal support in its House passage and passed unanimously out of its Senate committee. I will not back down from a bill that holds the government accountable and provides taxpayers the transparency they deserve.” The leaked markup has led to observers wondering whether the White House wants to scuttle the DATA Act and others to potentially withdraw support. “OMB’s version of the DATA Act is not a bill that the Sunlight Foundation can support,” wrote Matt Rumsey, a policy analyst at the Sunlight Foundation. “If OMB’s suggestions are ultimately added to the legislation, we will join our friends at the Data Transparency Coalition and withdraw our support of the DATA Act.” In response to repeated questions about the leaked draft, the OMB press office has sent the same statement to multiple media outlets: “The Administration believes data transparency is a critical element to good government, and we share the goal of advancing transparency and accountability of Federal spending. We will continue to work with Congress and other stakeholders to identify the most effective & efficient use of taxpayer dollars to accomplish this goal.” I have asked the Office of Management and Budget (OMB) about all of these issues and will publish any reply I receive separately, with a link from this post.
Opening IRS e-file data would add innovation and transparency to $1.6 trillion U.S. nonprofit sector
One of the most important open government data efforts in United States history came into being in 1993, when citizen archivist Carl Malamud used a small planning grant from the National Science Foundation to license data from the Securities and Exchange Commission, published the SEC data on the Internet and then operated it for two years. At the end of the grant, the SEC decided to make the EDGAR data available itself — albeit not without some significant prodding — and has continued to do so ever since. You can read the history behind putting periodic reports of public corporations online at Malamud’s website, public.resource.org.

Two decades later, Malamud is working to make the law public, reform copyright, and free up government data again, buying, processing and publishing millions of public tax filings from nonprofits to the Internal Revenue Service. He has made the bulk data from these efforts available to the public and anyone else who wants to use it.
“This is exactly analogous to the SEC and the EDGAR database,” Malamud told me, in an phone interview last year. The trouble is that data has been deliberately dumbed down, he said. “If you make the data available, you will get innovation.”
November Form 990s now ready. http://t.co/HDoMzPjpY0 We have 7,335,804 Form 990s available. *STILL* no word from the IRS.
— Carl Malamud (@carlmalamud) January 4, 2014
Making millions of Form 990 returns free online is not a minor public service. Despite many nonprofits file their Form 990s electronically, the IRS does not publish the data. Rather, the government agency releases images of millions of returns formatted as .TIFF files onto multiple DVDs to people and companies willing and able to pay thousands of dollars for them. Services like Guidestar, for instance, acquire the data, convert it to PDFs and use it to provide information about nonprofits. (Registered users view the returns on their website.)
As Sam Roudman reported at TechPresident, Luke Rosiak, a senior watchdog reporter for the Washington Examiner, took the files Malamud published and made them more useful. Specifically, he used credits for processing that Amazon donated to participants in the 2013 National Day of Civic Hacking to make the .TIFF files text-searchable. Rosiak then set up CItizenAudit.org a new website that makes nonprofit transparency easy.
“This is useful information to track lobbying,” Malamud told me. “A state attorney general could just search for all nonprofits that received funds from a donor.”
Malamud estimates nearly 9% of jobs in the U.S. are in this sector. “This is an issue of capital allocation and market efficiency,” he said. “Who are the most efficient players? This is more than a CEO making too much money — it’s about ensuring that investments in nonprofits get a return.
Malamud’s open data is acting as a platform for innovation, much as legislation.gov.uk is the United Kingdom. The difference is that it’s the effort of a citizen that’s providing the open data, not the agency: Form 990 data is not on Data.gov.
Opening Form 990 data should be a no-brainer for an Obama administration that has taken historic steps to open government data. Liberating nonprofit sector data would provide useful transparency into a $1.6 trillion dollar sector for the U.S. economy.
After many letters to the White House and discussions with the IRS, however, Malamud filed suit against the IRS to release Form 990 data online this summer.
“I think inertia is behind the delay,” he told me, in our interview. “These are not the expense accounts of government employees. This is something much more fundamental about a $1.6 trillion dollar marketplace. It’s not about who gave money to a politician.”
If I order these IRS DVDs, my cost is $2910. Media and gov get them free, but none of them lifting a finger to help. http://t.co/B6m5VECV1O
— Carl Malamud (@carlmalamud) January 22, 2014
When asked for comment, a spokesperson for the White House Office of Management and Budget said that the IRS “has been engaging on this topic with interested stakeholders” and that “the Administration’s Fiscal Year 2014 revenue proposals would let the IRS receive all Form 990 information electronically, allowing us to make all such data available in machine readable format.”
Today, Malamud sent a letter of complaint to Howard Shelanski, administrator of the Office of Information and Regulatory Affairs in the White House Office of Management and Budget, asking for a review of the pricing policies of the IRS after a significant increase year-over-year. Specifically, Malamud wrote that the IRS is violating the requirements of President Obama’s executive order on open data:
The current method of distribution is a clear violation of the President’s instructions to
move towards more open data formats, including the requirements of the May 9, 2013
Executive Order making “open and machine readable the new default for government
information.”I believe the current pricing policies do not make any sense for a government
information dissemination service in this century, hence my request for your review.
There are also significant additional issues that the IRS refuses to address, including
substantial privacy problems with their database and a flat-our refusal to even
consider release of the Form 990 E-File data, a format that would greatly increase the
transparency and effectiveness of our non-profit marketplace and is required by law.
It’s not clear at all whether the continued pressure from Malamud, the obvious utility of CitizenAudit.org or the bipartisan budget deal that President Obama signed in December will push the IRS to freely release open government data about the nonprofit sector,
The furor last summer over the IRS investigating the status of conservative groups claimed tax-exempt status, however, could carry over into political pressure to reform. If political groups were tax-exempt and nonprofit e-file data were published about them, it would be possible for auditors, journalists and Congressional investigators to detect patterns. The IRS would need to be careful about scrubbing the data of personal information: last year, the IRS mistakenly exposed thousands of Social Security numbers when it posted 527 forms online — an issue that Malamud, as it turns out, discovered in an audit.
“This data is up there with EDGAR, in terms of its potential,” said Malamud. “There are lots of databases. Few are as vital to government at large. This is not just about jobs. It’s like not releasing patent data.”
If the IRS were to modernize its audit system, inspector generals could use automated predictive data analysis to find aberrations to flag for a human to examine, enabling government watchdogs and investigative journalists to potentially detect similar issues much earlier.
That level of data-driven transparency remains in the future. In the meantime, CitizenAudit.org is currently running on a server in Rosiak’s apartment.
Whether the IRS adopts it as the SEC did EDGAR remains to be seen.
[Image Credit: Meals on Wheels]
U.K. National Archives makes ‘good law’ online, builds upon open data as a platform

This September, I visited the United Kingdom’s Ministry of Justice and looked at the last remaining section of the Magna Carta that remains in effect. I was not, however, in a climate-controlled reading room, looking at a parchment or sheepskin.

Rather, I was sitting in the Ministry’s sunny atrium, where John Sheridan was showing me the latest version of the seminal legal document, now living on online, on his laptop screen. The remaining section that is in force is rather important to Western civilization and the rule of law as many citizens in democracies now experience it:
NO Freeman shall be taken or imprisoned, or be disseised of his Freehold, or Liberties, or free Customs, or be outlawed, or exiled, or any other wise destroyed; nor will We not pass upon him, nor [X1condemn him,] but by lawful judgment of his Peers, or by the Law of the Land. We will sell to no man, we will not deny or defer to any man either Justice or Right.
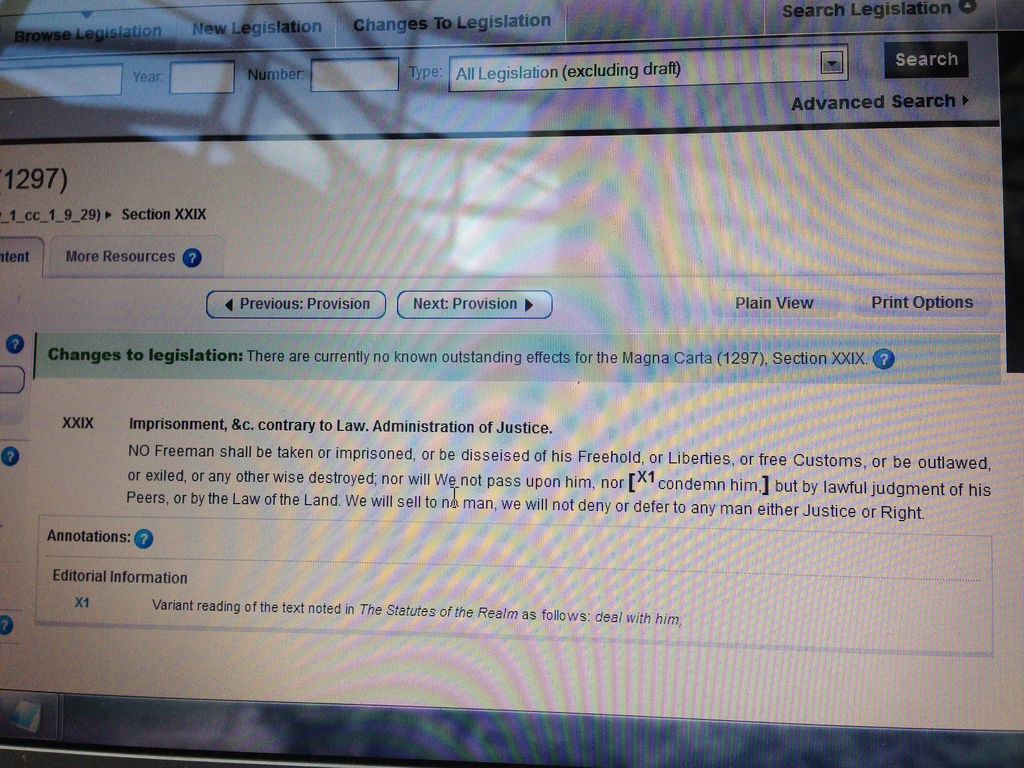
From due process to eminent domain to a right to a jury trial, many of the rights that American or British citizens take as a given today have their basis in the English common law that stems from this document.
I’d first met Sheridan virtually, back in August 2010, when I talked with the head of e-services and strategy at the United Kingdom’s National Archives about how linked data was opening up eight hundred years of legal history. That month, the National Archives launched legislation.gov.uk to provide public access to more than eight centuries of the legal history in England, Scotland, Wales and Northern Ireland. Just over three years later, I stepped off the Tube at the St. James Park Station and walked over to meet him in person and learn how his aspirations for legislation.gov.uk had met up with reality.
Over a cup of tea, Sheridan caught me up on the progress that his team has made in digitizing documents and improving the laws of the land. There are now 2 million monthly unique visitors to legislation.gov.uk every month, with 500+ million page views annually. People really are reading Parliament’s output, he observed, and increasingly doing so on tablets and mobile devices. The amount of content flowing into the site is considerable: according to Sheridan, the United Kingdom is passing laws at an estimated rate of 100,000 words every month, or twice as much as the complete works of Shakespeare.
Notable improvements over the years include the ability to compare the original text of legislation versus the latest version (as we did with the Magna Carta) and view a timeline of changes using a slider for navigation, exploring any given moment in time. Sheridan was particularly proud of the site’s rendering of legislation in HTML, include human-readable permanent uniform resource locators (URLS) and the capacity to produce on-demand PDFs of a given document. (This isn’t universally true: I found some orders appear still as PDFs).
More specifically, Sheridan highlighted a “good law” project, wherein the Office of the Parliamentary Counsel (OPC) of Britain is working to help develop plain language laws that are “necessary, clear, coherent, effective and accessible.” A notable component of this good law project is an effort to apply a tool used in online publishing, software development and advertising — A/B testing — to testing different versions of legislation for usability.
The video of a TedX talk embedded below by Richard Heaton, the permanent secretary of the United Kingdom’s Cabinet Office and first parliamentary counsel, explores the idea of “good law” at more length:
Sheridan went on to describe one of the more ambitious online collaborations between a government and its citizens I had heard of to date, a novel cross-Atlantic challenge co-sponsored by the UK and US governments, and a hairy legal technology challenge bearing down upon societies everywhere: what happens when software interprets the law?
For instance, he suggested, consider the increasing use of Oracle software around legislation. “As statutes are interpreted by software, what’s introduced by the code? What about quality testing?”
As this becomes a data problem, “you need information to contextualize it,” said Sheridan. “If you’re thinking about legislation as code, and as data, it raises huge questions for the rule of law.”
Open data as a platform
In the video below, John Sheridan talks about the benefits of opening up government data using application programming interfaces:
Sheridan has been one of the world’s foremost proponents of publishing legislative data through APIs, an approach that has come under criticism by open government data advocates after the government shutdown in the United States. (In 2014, forward-thinking governments publishing open data might consider provide basic visualization tools to site visitors, API access for third-party developers and internal users, and bulk data downloads.) One key difference between the approach of his team and other government entities might be that the National Archives are “dogfooding,” or consuming the same data through the same interface that they expect third-parties to use, as Sheridan wrote last March:
“We developed the API and then built the legislation.gov.uk website on top of it. The API isn’t a bolt-on or additional feature, it is the beating heart of the service. Thanks to this approach it is very easy to access legislation data – just add /data.xml or /data.rdf to any web page containing legislation, or /data.feed, to any list or search results. One benefit of this approach is that the website, in a way, also documents the API for developers, helping them understand this complex data.”
Perhaps because of that perspective, Sheridan, was as supportive of an APIs when we talked this September as he had been in 2012:
The legislation.gov.uk API has changed everything for us. It powers our website. It has enabled us to move to an open data business model, securing the editorial effort we need from the private sector for this important source of public data. It allows us to deliver information and services across channels and platforms through third party applications. We are developing other tools that use the API, using Linked Data – from recording the provenance of new legislation as it is converted from one format to another, to a suite of web based editorial tools for legislation, including a natural language processing capability that automatically identifies the legislative effects. Everything we do is underpinned by the API and Linked Data. With the foundations in place, the possibilities of what can be done with legislation data are now almost limitless.
Sheridan noted to me that the United Kingdom’s legislative open government data efforts are now acting as a platform for large commercial legal publishers and new entrants, like mobile legislative app, iLegal.
 The iLegal app content is derived from the legislation.gov.uk API and offers handy features, like offline access to all items of legislation. iLegal currently costs £49.99/$74.99 annually or £149.99/$219.99 for a lifetime subscription, which might seem steep but is a fraction of the cost of of Halsbury’s Statutes, currently listed at £9,360.00 from Lexis-Nexis.
The iLegal app content is derived from the legislation.gov.uk API and offers handy features, like offline access to all items of legislation. iLegal currently costs £49.99/$74.99 annually or £149.99/$219.99 for a lifetime subscription, which might seem steep but is a fraction of the cost of of Halsbury’s Statutes, currently listed at £9,360.00 from Lexis-Nexis.
This approach to publishing the laws of the land online, in structured form under an open license, is an instantiation of the vision for Law.gov that citizen archivist Carl Malamud has been advocating for in the United States. 2013 saw some progress in that vein when the U.S. House of Representatives publishes U.S. Code as open government data.)
What’s notable about the United Kingdom’s example, however, is that less then a decade ago, none of this could have been possible. Why? As ScraperWiki founder Francis Irving explained, the UK’s database of laws was proprietary data until December 2006. Now, however, the law of the land is released back to the people as it is updated, a living code available in digital form to any member of the public that wishes to read or reuse it.
The United Kingdom, however, has moved beyond simply publishing legislation as open data: they’re actively soliciting civic participation in its maintenance and improvement. For the last year, the National Archives has been guiding the world’s leading commercial open data curation project.
“We are using open data as business model for fulfilling public services,” said Sheridan, in our interview. “We train people to do editorial work. They are paid to improve data. The outputs are public.”
In other words, the open government data always remains free to the people through legislation.gov.uk but any academic, nonprofit or commercial entity can act to add value to it and sell access to the resulting applications, analyses or interfaces.
As far as Sheridan could recall, this was the only such example in the government of the United Kingdom where such a feedback loop exist. The closest parallels in the United States is the U.S. Agency for International Development crowdsourcing geocoding 117,000 loan records with the help of online volunteers [Case Study] or the citizen archivist program of the U.S. National Archives.
Since the start of the UK project, they have doubled the number of people working on their open data, Sheridan told me. “The bottleneck is training,” he said. “We have almost unlimited editorial expertise available through our website. We define the process and rules, and then let anyone contribute. For example, we’re now working on revising legislation, identifying changes, researching it — when it comes in, what it affects — and then working with editor. Previous to this effort, government hasn’t been able to revise secondary legislation.”
Sheridan said that the next step is feedback for other editorial values.
“We’re looking for more experts,” he said. “They’re generally paid for by someone. It’s very close to open source software model. They must be able to demonstrate competence. There’s a 45-minute test, which we’re now given to thousands of people.”
If this continues to work, distributed online collaboration is a “brilliant way to help improve the quality of law,” said Sheridan.
“It’s a way to get the work done — and the work is really hard. You have to invest time and energy, and you must protect the reputation of the Archive. This is somewhat radical for the nation’s statute book. We have redesigned the process so people can work with us. It’s not a wiki, but participation is open. It’s peer production.”
A trans-Atlantic challenge to map legislative data

In September, Sheridan also told me about an unusual challenge that has just gone live at Challenge.gov, the United States’ flagship prizes and competitions platform: a contest to assess the compatibility of Akoma Ntoso with U.S. Congress and U.K. Parliament markup languages.
Second Library of Congress Legislative Data Challenge Launched, with US and UK Bills. See: http://t.co/t5ZrN3k0sp cc @digiphile
— legislation.gov.uk (@legislation) September 20, 2013
The U.K. National Archives and U.S. Library of Congress have asked for help mapping elements from bills to the most recent Akoma Ntoso schema. (Akoma Ntoso is an emerging global standard for machine-readable data describing parliamentary, legislative and judiciary documents.) The best algorithm that maps U.S. bill XML or UK bill XML to Akoma Ntoso XML, including necessary data files and supporting documentation, will win $10,000.
If you have both skills and interest, get cracking: the challenge closes on December 31, 2013.
U.S. House of Representatives publishes U.S. Code as open government data

Three years on, Republicans in Congress continue to follow through on promises to embrace innovation and transparency in the legislative process. Today, the United States House of Representatives has made the United States Code available in bulk Extensible Markup Language (XML).
“Providing free and open access to the U.S. Code in XML is another win for open government,” said Speaker John Boehner and Majority Leader Eric Cantor, in a statement posted to Speaker.gov. “And we want to thank the Office of Law Revision Counsel for all of their work to make this project a reality. Whether it’s our ‘read the bill’ reforms, streaming debates and committee hearings live online, or providing unprecedented access to legislative data, we’re keeping our pledge to make Congress more transparent and accountable to the people we serve.”
House Democratic leaders praised the House of Representatives Office of the Law Revision Counsel (OLRC) for the release of the U.S. Code in XML, demonstrating strong bipartisan support for such measures.
“OLRC has taken an important step towards making our federal laws more open and transparent,” said Whip Steny H. Hoyer, in a statement.
“Congress has a duty to publish our collective body of enacted federal laws in the most modern and accessible way possible, which today means publishing our laws online in a structured, digital format. I congratulate the OLRC for completing this significant accomplishment. This is another accomplishment of the Legislative Branch Bulk Data Task Force. The Task Force was created in a bipartisan effort during last year’s budget process. I want to thank Reps. Mike Honda and Mike Quigley for their leadership in this area, and Speaker Boehner and Leader Cantor for making this task force bipartisan. I also want to commend the dedicated civil servants who are leading the effort from the non-partisan legislative branch agencies, like OLRC, who work diligently behind the scenes – too often without recognition – to keep Congress working and moving forward.”
The reaction from open government advocates was strongly positive.
“Today’s announcement is another milestone in the House of Representatives efforts to modernize how legislative information is made available to the American people,” said Daniel Schuman, policy director at Citizens for Responsibility and Ethics in Washington (CREW). “The release of the US Code in Bulk XML is the culmination of several years of work, and complements the House’s efforts to publish House floor and committee data online, in real time, and in machine readable formats. Still awaiting resolution – and the focus of the transparency community’s continuing efforts — is the bulk release of legislative status information.” (More from Schuman at the CREW blog.)
“I think they did an outstanding job,” commented Eric Mill, a developer at the Sunlight Foundation. “Historically, the U.S. Code has been extremely difficult to reliably and accurately use as data. These new XML files are sensibly designed, thoroughly documented, and easy to use.”
The data has already been ingested into open government websites.
“Just this morning, Josh Tauberer updated our public domain U.S. Code parser to make use of the new XML version of the US Code,” said Mill. “The XML version’s consistent design meant we could fix bugs and inaccuracies that will contribute directly to improving the quality of GovTrack’s and Sunlight’s work, and enables more new features going forward that weren’t possible before. The public will definitely benefit from the vastly more reliable understanding of our nation’s laws that today’s XML release enables.” (More from Tom Lee at the Sunlight Labs blog.)
Jim Harper, Director of Information Policy Studies at the Cato Institute, similarly applauded the release.
“This is great progress toward better public oversight of government,” he said. “Having the U.S. Code in XML can allow websites, apps, and information services to weave together richer stories about how the law applies and how Congress is thinking about changing it.”
Harper also contrasted the open government efforts of the Obama administration, which has focused more upon the release of open government data relevant to services, with that of the House of Representatives. While the executive and legislative branches are by definition apples and oranges, the comparison has value.
“Last year, we reported that House Republicans had the transparency edge on Senate Democrats and the Obama administration,” he said. “(House Democrats support the Republican leadership’s efforts.) The release of the U.S. Code in XML joins projects like docs.house.gov and beta.congress.gov in producing actual forward motion on transparency in Congress’s deliberations, management, and results.
For over a year, I’ve been pointing out that there is no machine-readable federal government organization chart. Having one is elemental transparency, and there’s some chance that the Obama administration will materialize with the Federal Program Inventory. But we don’t know yet if agency and program identifiers will be published. The Obama administration could catch up or overtake House Republicans with a little effort in this area. Here’s hoping they do.”
This article has been updated with additional statements over time.
