According to Liang, as of June 2014 they were “the only place besides Healthcare.gov where this is possible. We have signed an agreement with CMS as a web based entity to do this. We are directly integrated with the federal data hub, so going through us is identical to going through Healthcare.gov.”
This September, I visited the United Kingdom’s Ministry of Justice and looked at the last remaining section of the Magna Carta that remains in effect. I was not, however, in a climate-controlled reading room, looking at a parchment or sheepskin.
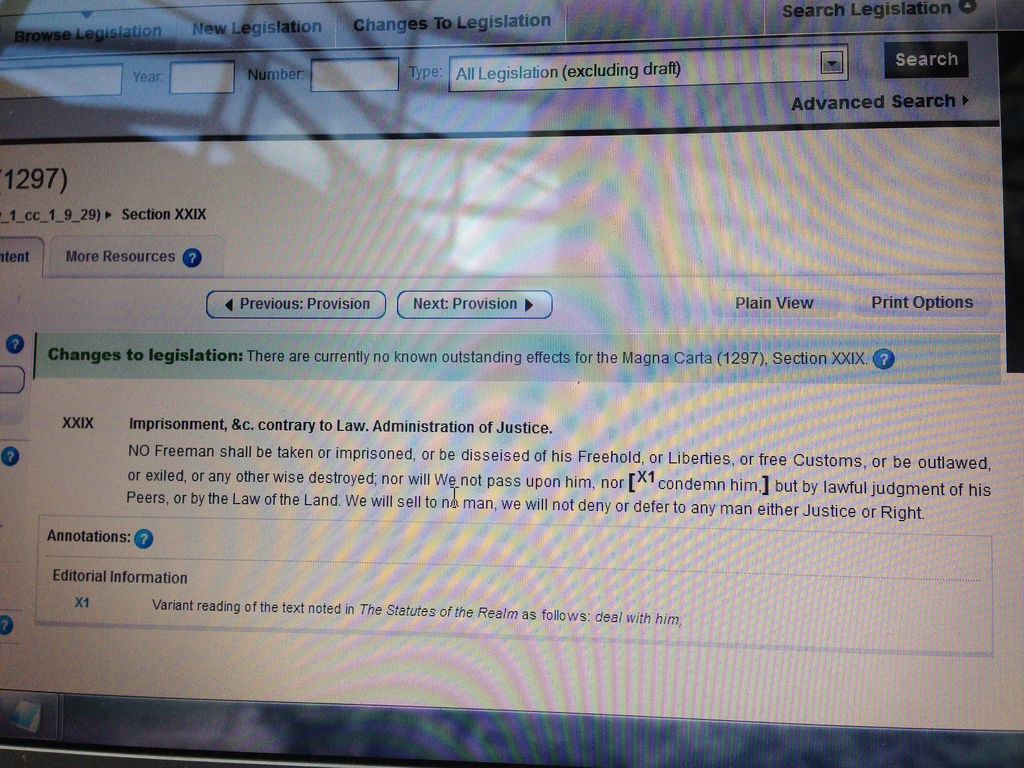
Rather, I was sitting in the Ministry’s sunny atrium, where John Sheridan was showing me the latest version of the seminal legal document, now living on online, on his laptop screen. The remaining section that is in force is rather important to Western civilization and the rule of law as many citizens in democracies now experience it:
NO Freeman shall be taken or imprisoned, or be disseised of his Freehold, or Liberties, or free Customs, or be outlawed, or exiled, or any other wise destroyed; nor will We not pass upon him, nor [X1condemn him,] but by lawful judgment of his Peers, or by the Law of the Land. We will sell to no man, we will not deny or defer to any man either Justice or Right.
From due process to eminent domain to a right to a jury trial, many of the rights that American or British citizens take as a given today have their basis in the English common law that stems from this document.
Over a cup of tea, Sheridan caught me up on the progress that his team has made in digitizing documents and improving the laws of the land. There are now 2 million monthly unique visitors to legislation.gov.uk every month, with 500+ million page views annually. People really are reading Parliament’s output, he observed, and increasingly doing so on tablets and mobile devices. The amount of content flowing into the site is considerable: according to Sheridan, the United Kingdom is passing laws at an estimated rate of 100,000 words every month, or twice as much as the complete works of Shakespeare.
Notable improvements over the years include the ability to compare the original text of legislation versus the latest version (as we did with the Magna Carta) and view a timeline of changes using a slider for navigation, exploring any given moment in time. Sheridan was particularly proud of the site’s rendering of legislation in HTML, include human-readable permanent uniform resource locators (URLS) and the capacity to produce on-demand PDFs of a given document. (This isn’t universally true: I found some orders appear still as PDFs).
More specifically, Sheridan highlighted a “good law” project, wherein the Office of the Parliamentary Counsel (OPC) of Britain is working to help develop plain language laws that are “necessary, clear, coherent, effective and accessible.” A notable component of this good law project is an effort to apply a tool used in online publishing, software development and advertising — A/B testing — to testing different versions of legislation for usability.
The video of a TedX talk embedded below by Richard Heaton, the permanent secretary of the United Kingdom’s Cabinet Office and first parliamentary counsel, explores the idea of “good law” at more length:
Sheridan went on to describe one of the more ambitious online collaborations between a government and its citizens I had heard of to date, a novel cross-Atlantic challenge co-sponsored by the UK and US governments, and a hairy legal technology challenge bearing down upon societies everywhere: what happens when software interprets the law?
For instance, he suggested, consider the increasing use of Oracle software around legislation. “As statutes are interpreted by software, what’s introduced by the code? What about quality testing?”
As this becomes a data problem, “you need information to contextualize it,” said Sheridan. “If you’re thinking about legislation as code, and as data, it raises huge questions for the rule of law.”
Sheridan has been one of the world’s foremost proponents of publishing legislative data through APIs, an approach that has come under criticism by open government data advocates after the government shutdown in the United States. (In 2014, forward-thinking governments publishing open data might consider provide basic visualization tools to site visitors, API access for third-party developers and internal users, and bulk data downloads.) One key difference between the approach of his team and other government entities might be that the National Archives are “dogfooding,” or consuming the same data through the same interface that they expect third-parties to use, as Sheridan wrote last March:
“We developed the API and then built the legislation.gov.uk website on top of it. The API isn’t a bolt-on or additional feature, it is the beating heart of the service. Thanks to this approach it is very easy to access legislation data – just add /data.xml or /data.rdf to any web page containing legislation, or /data.feed, to any list or search results. One benefit of this approach is that the website, in a way, also documents the API for developers, helping them understand this complex data.”
Perhaps because of that perspective, Sheridan, was as supportive of an APIs when we talked this September as he had been in 2012:
The legislation.gov.uk API has changed everything for us. It powers our website. It has enabled us to move to an open data business model, securing the editorial effort we need from the private sector for this important source of public data. It allows us to deliver information and services across channels and platforms through third party applications. We are developing other tools that use the API, using Linked Data – from recording the provenance of new legislation as it is converted from one format to another, to a suite of web based editorial tools for legislation, including a natural language processing capability that automatically identifies the legislative effects. Everything we do is underpinned by the API and Linked Data. With the foundations in place, the possibilities of what can be done with legislation data are now almost limitless.
Sheridan noted to me that the United Kingdom’s legislative open government data efforts are now acting as a platform for large commercial legal publishers and new entrants, like mobile legislative app, iLegal.
The iLegal app content is derived from the legislation.gov.uk API and offers handy features, like offline access to all items of legislation. iLegal currently costs £49.99/$74.99 annually or £149.99/$219.99 for a lifetime subscription, which might seem steep but is a fraction of the cost of of Halsbury’s Statutes, currently listed at £9,360.00 from Lexis-Nexis.
This approach to publishing the laws of the land online, in structured form under an open license, is an instantiation of the vision for Law.gov that citizen archivist Carl Malamud has been advocating for in the United States. 2013 saw some progress in that vein when the U.S. House of Representatives publishes U.S. Code as open government data.)
What’s notable about the United Kingdom’s example, however, is that less then a decade ago, none of this could have been possible. Why? As ScraperWiki founder Francis Irving explained, the UK’s database of laws was proprietary data until December 2006. Now, however, the law of the land is released back to the people as it is updated, a living code available in digital form to any member of the public that wishes to read or reuse it.
The United Kingdom, however, has moved beyond simply publishing legislation as open data: they’re actively soliciting civic participation in its maintenance and improvement. For the last year, the National Archives has been guiding the world’s leading commercial open data curation project.
“We are using open data as business model for fulfilling public services,” said Sheridan, in our interview. “We train people to do editorial work. They are paid to improve data. The outputs are public.”
In other words, the open government data always remains free to the people through legislation.gov.uk but any academic, nonprofit or commercial entity can act to add value to it and sell access to the resulting applications, analyses or interfaces.
Since the start of the UK project, they have doubled the number of people working on their open data, Sheridan told me. “The bottleneck is training,” he said. “We have almost unlimited editorial expertise available through our website. We define the process and rules, and then let anyone contribute. For example, we’re now working on revising legislation, identifying changes, researching it — when it comes in, what it affects — and then working with editor. Previous to this effort, government hasn’t been able to revise secondary legislation.”
Sheridan said that the next step is feedback for other editorial values.
“We’re looking for more experts,” he said. “They’re generally paid for by someone. It’s very close to open source software model. They must be able to demonstrate competence. There’s a 45-minute test, which we’re now given to thousands of people.”
If this continues to work, distributed online collaboration is a “brilliant way to help improve the quality of law,” said Sheridan.
“It’s a way to get the work done — and the work is really hard. You have to invest time and energy, and you must protect the reputation of the Archive. This is somewhat radical for the nation’s statute book. We have redesigned the process so people can work with us. It’s not a wiki, but participation is open. It’s peer production.”
A trans-Atlantic challenge to map legislative data
The U.K. National Archives and U.S. Library of Congress have asked for help mapping elements from bills to the most recent Akoma Ntoso schema. (Akoma Ntoso is an emerging global standard for machine-readable data describing parliamentary, legislative and judiciary documents.) The best algorithm that maps U.S. bill XML or UK bill XML to Akoma Ntoso XML, including necessary data files and supporting documentation, will win $10,000.
If you have both skills and interest, get cracking: the challenge closes on December 31, 2013.
Day by day, we are gaining better maps and tools to navigate the complexities of world around us. The ways that open data is finding its way into the hands of citizens and consumers were described today in a new reportfrom a federal interagency task force on “smart disclosure.”
Smart disclosure, for those unfamiliar, is a term of art for when a private company or government agency provides you with access to your own data in a format that enables you to put the data to use.
According to federal officials, this report from the National Science and Technology Council is the “first comprehensive description of the Federal Government’s efforts to promote the smart disclosure of information that can help consumers make wise decisions in the marketplace.” If you’re interested in the topic, it’s one of the most clearly written government documents I’ve come across lately: give it a read.
As Alex Fitzpatrick pointed out in his post on the ways companies are using government data, however, the report didn’t include the names of specific companies.
The administration’s top IT officials — chief information officer Steven VanRoekel and chief technology officer Todd Park — say that open data is good for America. If its release supports or leads to the creation of more startups that create products and services that improve people’s lives, that assertion will be born out.
If you recognize other startups from the descriptions in Alex’s post, please drop him a comment or a tweet — and if you use open government data in your startup, nonprofit or enterprise, please let us know in the comments.
This morning, the White House released a new executive order from President Barack Obama that makes “open and machine readable” the new default for the release of government information.
The White House also published a memorandum regarding the policy that goes with it and a new website on Github that offers more context and resources on Project Open Data.
One big question is whether data that is currently being bought by big business and startups — or obtained under FOIA — is now identified and released. Business interest in government data is longstanding, from Bloomberg to Reuters to Lexis-Nexis. New players exist now, particularly Google, and I expect them to consume data as it becomes available and make it usable, useful and economically significant.
At a broader level, the new policy defines machine-readable as the default and instructs agencies to do data inventories. That may sounds simple, to a layman, but it’s a big deal, if the administration can drive implementation and make this more than another compliance exercise.
Open data is to the 21st century as the highway system was to the 20th. POTUS recognizes this with an executive order 1.usa.gov/147Avxo
We’ll see. John Wonderlich is right: this open data executive order is a step in the right direction and shows a path forward.
Later today, the President is going to talk about this order in Texas, elevating open data into the national discussion. I expect the conversation that results to be interesting. I’ll be speaking with the US CIO as well, so if you have questions, please let me know at @digiphile on Twitter or weigh in in the comments.
In the network graph below, you’ll see there are 3 discreet groups around the White House, Tim O’Reilly and me, and Michelle Malkin. The lines between the nodes show replies.
On Friday night, a packed room of eager potential entrepreneurs, developers and curious citizens watched US CTO Todd Park and Bill Eggers kick off Startup Weekend DC in Microsoft’s offices in Chevy Chase, Maryland.
//platform.twitter.com/widgets.jsPark brought his customary energy and geeky humor to his short talk, pitching the assembled crowd on using open government data in their ideas.
Park wants to inject open data as a “fuel” into the economy. After talking about the success of the Health Data Initiative and the Health Datapalooza, he shared a series of websites were aspiring entrepreneurs could find data to use:
Park also made an “ask” of the attendees of Startup Weekend DC that I haven’t heard from many government officials: he requested that if they A) use the data and/or B) if they run into any trouble accessing it, to let him know.
“If you had a hard time or found a particular restful API moving, let me know,” he said. “It helps us improve our performance.” And then he gave out his email address at the White House Executive Office of the President, as he did at SXSW Interactive in Austin in March of this year. Asking the public for feedback on data quality — particularly entrepreneurs and developers — and providing contact information to do so is, to put it bluntly, something every city and state official that has stood up and open data platform could and should be doing. In this context, the US CTO has set a notable example for the country.
Examples of startups, gap filling and civic innovation
Following Park, author and Deloitte consultant Bill Eggers talked about innovative startups and the public sector. I’ve embedded video of his talk below:
Eggers cited three different startups in his talk: Recycle Bank, Avego and Kaggle.
1) The outcome of Recycle Bank‘s influence was a 19-fold increase in recycling in some cities from gamification, said Eggers. The startup now has 3 million members and is now setting its sights on New York City.
2) The real-time ridesharing provided by Avego holds the promise to hugely reduce traffic congestion, said Eggers. According to the stats he cited, 80% of people on the road are currently driving in cars by themselves. Avego has raised tens of millions of dollars to try to better optimize transportation.
3) Anthony Goldbloom found a hole in the big data market at Kaggle, said Eggers, where they’re matching data challenges with data scientists. There now some 19,000 registered data scientists in the Kaggle database.
Eggers cited the success of a competition to map dark matter on Kaggle, a problem that had had millions spent on it. The results of open innovation here were better than science had been able to achieve prior to the competition. Kaggle has created a market out of writing better algorithms.
//platform.twitter.com/widgets.jsAfter Eggers spoke, the organizers of Startup Weekend explained how the rest of the weekend would proceed and asked attendees to pitch their ideas. One particular idea, for this correspondent, stood out, primarily because of the young fellows pitching it:
President Barack Obama in the Oval Office, Jan. 4, 2011. (Official White House Photo by Pete Souza)
On January 18, 2011, President Obama issued an executive order directing that regulations shall be adopted through a process that involves participation. 13 months later, the nation’s primary online regulatory website received an overdue redesign and, significantly, a commitment from the administrator of the White House Office of Information and Regulatory Affairs (OIRA) to make regulatory data available to the public.
…the President issues Executive Order 13563, in which he directed regulatory agencies to base regulations on an “open exchange of information and perspectives” and to promote public participation in Federal rulemaking. The President identified Regulations.gov as the centralized portal for timely public access to regulatory content online.
In response to the President’s direction, Regulations.gov has launched a major redesign, including innovative new search tools, social media connections, and better access to regulatory data. The result is a significantly improved website that will help members of the public to engage with agencies and ultimately to improve the content of rules.
The redesign of Regulations.gov also fulfills the President’s commitment in The Open Government Partnership National Action Plan to “improve public services,” including to “expand public participation in the development of regulations.” This step is just one of many, consistent with the National Action Plan, designed to make our Federal Government more transparent, participatory, and collaborative.
I’ve embedded the video that Regulations.gov released about the launch below:
New Application Programming Interfaces (APIs) and standard, Federal Register-specific URLs.
That last detail will be of particular interest to the open government and open data community. Sunstein explained the thinking behind the role of APIs at the WhiteHouse.gov blog:
Application Programming Interfaces (APIs) are technical interfaces/tools that allow people to pull regulatory content from Regulations.gov. For most of us, the addition of “APIs” on Regulations.gov doesn’t mean much, but for web managers and experts in the applications community, providing APIs will fundamentally change the way people will be able to interact with public federal regulatory data and content.
The initial APIs will enable developers to pull data out of Regulations.gov, and in future releases, the site will include APIs for receiving comment submissions from other sites. With the addition of APIs, other web sites – ranging from other Government sites to industry associations to public interest groups – will now be able to repurpose publicly-available regulatory information on Regulations.gov, and format this information in unique ways such as mobile apps, analytical tools, “widgets” and “mashups.” We don’t know exactly where this will lead us – technological advances are full of surprises – but we are likely to see major improvements in public understanding and participation in rulemaking.
While the APIs will need to be explored and the data behind them assessed for quality, releasing regulatory data through APIs could in theory underpin a wide variety of new consumer-facing services. If you’re interested in the APIs, click on “Developers – Beta” at Regulations.gov to download a PDF with that contains API directions, URLs and information about an API Key.
A time for e-rulemaking
This move comes as part of a larger effort towards e-rulemaking by this White House that will almost certainly be carried over into future administrations, regardless of the political persuasion of the incumbent of the Oval Office. In the 21st century, the country desperately needs a smarter approach to regulations.
As the Wall Street Journal reported last year, the ongoing regulatory review by OIRA is a nod to serious, long-standing concerns in the business community about excessive regulation hampering investment and job creation as citizens struggle to recover from the effects of the Great Recession.
We’ll see if an upgraded online portal that is being touted as a means to include the public in participating in rulemaking makes any difference in regulatory outcomes. Rulemaking and regulatory review are, virtually by their nature, wonky and involve esoteric processes that rely upon knowledge of existing laws and regulations.
While the Internet could involve many more people in the process, improved outcomes will depend upon an digitally literate populace that’s willing to spend some of its civic surplus on public participation.
To put it another way, getting to “Regulations 2.0” will require “Citizen 2.0” — and we’ll need the combined efforts of all our schools, universities, libraries, non-profits and open government advocates to have a hope of successfully making that upgrade.
Dr. Peter Parycek (@parycek shared his presentation on open government data today. If you’re interested in an Austrian perspective on the growth of open government data, you’ll find it interesting. (A good bit of German required near the end.)
Parycek is affiliated with the Center for E-Government at Danube University in Germany and writes at the Digital Government blog. As he shares at the end of the presentation, there’s a Gov 2.0 Camp in Vienna on December 2nd. If you’re interested in open data and nearby, that sounds like an optimal place to connect with other people in this growing international community.
If you’re a regular reader of Govfresh or the O’Reilly Radar, you know how the chief technology officer of the U.S. Department of Health and Human Services, Todd Park ,is focused on unleashing the power of open data to improve health. If you aren’t familiar with this story, go read Simon Owen’s excellent feature article that explores his work on revolutionizing the healthcare industry. Part of unlocking innovation through open health data has been a relentless promotion and evangelization of the data that HHS has to venture capitalists, the healthcare industry and developers. It was in that context that Park visited New York’s Hacks and Hackers meetup today. The video of the meeting is embedded below, including a lengthy question and answer period at the end.
NYC Hacks and Hackers co-organizer Chrys Wu was kind enough to ask my questions, posed over Twitter. Here were the answers I pulled out from the video above:
How much data has been released? Park: “A ton.” He pointed to HealthData.gov as a scorecard and said that HHS isn’t just releasing brand new data. They’re “also making existing data truly accessible or usable,” he said. They’re taking “stuff that’s in a book or website and turning it into machine readable data or an API.”
What formats? Park: Lots and lots of different formats. “Some people put spreadsheets online, other people actually create open APIs and open services,” he said. “We’re trying to migrate people as much towards open API as possible.”
Impact to date? “The best quantification that I can articulate is the Health data-palooza,” he said. “50 companies and nonprofits updated and deployed new versions of their platforms and services. The data already helping millions of Americans in all kinds of ways.”
Park emphasized that it’s still quite early for the project, at only 18 months into this. He also emphasized that the work isn’t just about data: it’s about how and where it’s used. “Data by itself isn’t useful. You don’t go and download data and slather data on yourself and get healed,” he said. “Data is useful when it’s integrated with other stuff that does useful jobs for doctors, patients and consumers.”
In one of the first posts on NASA’s newly relaunched open government blog, open government analyst Ali Llewellyn writes more about why adopting open government is important now, with a nod to Tim O’Reilly’s essay on “government as a platform.”
…OpenGov is not just data transparency or technology use. “Open government is an innovative strategy for changing how government works,” Beth Noveck, the original director of the White House Open Government Initiative, explains. “By using network technology to connect the public to government and to one another informed by open data, an open government asks for help with solving problems. The end result is more effective institutions and more robust democracy.”
From the beginning, democracy was supposed to be participatory. Thomas Jefferson noted in a letter how he envisioned a government where “every man…feels that he is a participator in the government of affairs, not merely at an election one day in the year, but every day.”
In the service of that vision, the National Aeronautics and Space Administration continues to extend its journey into the open government stratosphere with the launch of a redesigned open.nasa.gov. The new site complements nasa.gov/open – but doesn’t replace it. (The /open sites that exist on federal .gov websites are a direct result of the Open Goverment Directive issued by the White House Office of Management and Budget in 2009.)
The new NASA open government is a beautiful departure from standard NASA websites. In fact, it’s a lovely move away from the Web design citizens encounter at most of the thousands of federal .gov sites. In part, that’s because the new NASA open government site is built upon General Service Agency-approved technologies and the same open source platforms ( like WordPress) that you’ll find at top-notch blogs like BoingBoing. (Or Govfresh). All due credit to Nick Skytland, Chris Gerty and Sean Herron for their hard work coding and designing the site as well. Skytland, who now heads up open government at NASA, wrote in to share his vision for the site and make a request:
After months of development and many discussions, we are very excited to announce the official public launch of open.nasa.gov. The site is a collaborative platform for the open government community at NASA to share success stories and projects related OpenGov from around the agency. The content on this site is written by NASA employees and contractors (just the core OpenGov team right now). We will be highlighting the ways that transparency, participation, and collaboration are being embraced by NASA policy, technology, and culture, and the future that becomes possible because of that commitment. We would love your feedback on the site. Please let us know if you have any issues with the site so we can fix them. The site works on most browsers, but we are still working out issues with Internet Explorer.”
Aside from WordPress, the technology behind open.nasa.gov includes:
Techs used:
A WordPress theme by Landau Reece called Protean 1.0
MySQL
Apache
The Disqus commenting system
The UserVoice feedback collection tool
As I reported yesterday, NASA’s open government story now includes supplying the innovation behind OpenStack and Nebula. That said, while the technology behind the new NASA open government site and other initiatives is important to recognize, it has to be valued in terms of its ability to both host conversations and feature the people behind it. As NASA’s open government story evolves, cultural changes will be important to track, along with any technical milestones driven by open source or efficiencies driven by tightening budgets.
A note on FOIA
One of the interesting decisions that British Columbia’s government made in its adoption of open government was its decision to separate good government data, associated with transparency and accountability, from open government data, associated with innovation and co-creation.
NASA’s open government site makes no such distinction, with the link to Freedom of Information Act requests buried down at the bottom of the open data page. NASA’s open government plan includes aspirational goals of further reducing its FOIA backlog and creating a “single, Web-based system for handling all FOIA requests across the 13 NASA locations.” If the agency can do as well with that system as it has with the design, communication and coding embodied this new site, its open government team will be able to celebrate more good government achievement alongside its explorations into citizen science, random hacks of kindness, education and open data.








")

