

This September, I visited the United Kingdom’s Ministry of Justice and looked at the last remaining section of the Magna Carta that remains in effect. I was not, however, in a climate-controlled reading room, looking at a parchment or sheepskin.

Rather, I was sitting in the Ministry’s sunny atrium, where John Sheridan was showing me the latest version of the seminal legal document, now living on online, on his laptop screen. The remaining section that is in force is rather important to Western civilization and the rule of law as many citizens in democracies now experience it:
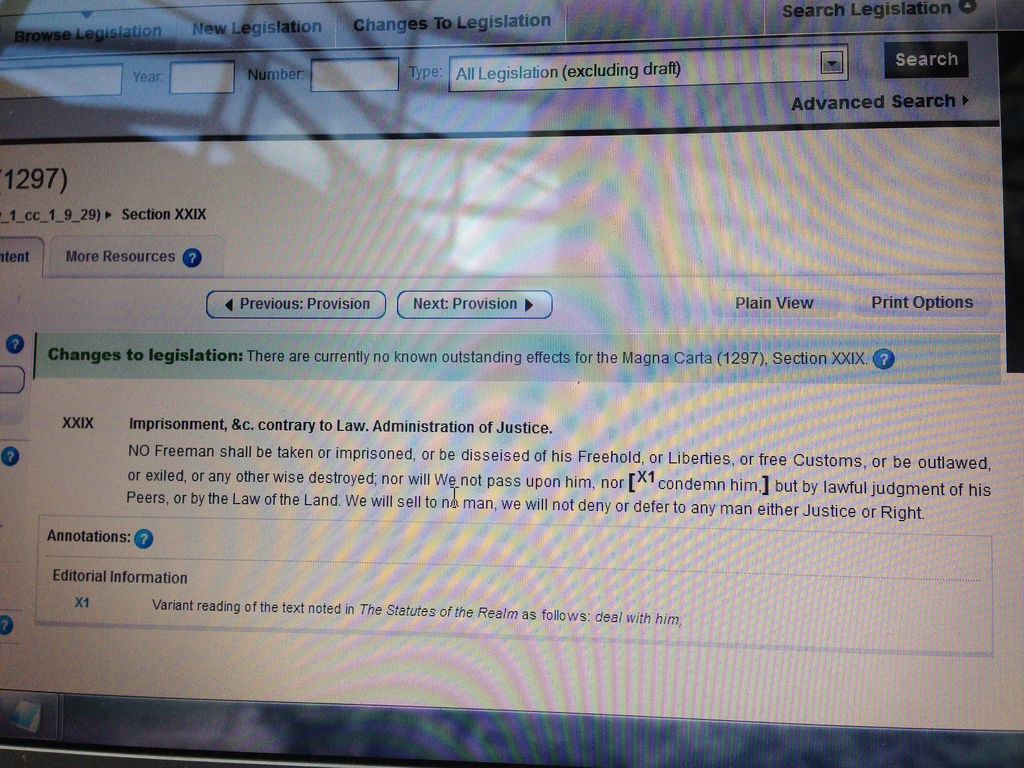
NO Freeman shall be taken or imprisoned, or be disseised of his Freehold, or Liberties, or free Customs, or be outlawed, or exiled, or any other wise destroyed; nor will We not pass upon him, nor [X1condemn him,] but by lawful judgment of his Peers, or by the Law of the Land. We will sell to no man, we will not deny or defer to any man either Justice or Right.
From due process to eminent domain to a right to a jury trial, many of the rights that American or British citizens take as a given today have their basis in the English common law that stems from this document.
I’d first met Sheridan virtually, back in August 2010, when I talked with the head of e-services and strategy at the United Kingdom’s National Archives about how linked data was opening up eight hundred years of legal history. That month, the National Archives launched legislation.gov.uk to provide public access to more than eight centuries of the legal history in England, Scotland, Wales and Northern Ireland. Just over three years later, I stepped off the Tube at the St. James Park Station and walked over to meet him in person and learn how his aspirations for legislation.gov.uk had met up with reality.
Over a cup of tea, Sheridan caught me up on the progress that his team has made in digitizing documents and improving the laws of the land. There are now 2 million monthly unique visitors to legislation.gov.uk every month, with 500+ million page views annually. People really are reading Parliament’s output, he observed, and increasingly doing so on tablets and mobile devices. The amount of content flowing into the site is considerable: according to Sheridan, the United Kingdom is passing laws at an estimated rate of 100,000 words every month, or twice as much as the complete works of Shakespeare.
Notable improvements over the years include the ability to compare the original text of legislation versus the latest version (as we did with the Magna Carta) and view a timeline of changes using a slider for navigation, exploring any given moment in time. Sheridan was particularly proud of the site’s rendering of legislation in HTML, include human-readable permanent uniform resource locators (URLS) and the capacity to produce on-demand PDFs of a given document. (This isn’t universally true: I found some orders appear still as PDFs).
More specifically, Sheridan highlighted a “good law” project, wherein the Office of the Parliamentary Counsel (OPC) of Britain is working to help develop plain language laws that are “necessary, clear, coherent, effective and accessible.” A notable component of this good law project is an effort to apply a tool used in online publishing, software development and advertising — A/B testing — to testing different versions of legislation for usability.
The video of a TedX talk embedded below by Richard Heaton, the permanent secretary of the United Kingdom’s Cabinet Office and first parliamentary counsel, explores the idea of “good law” at more length:
Sheridan went on to describe one of the more ambitious online collaborations between a government and its citizens I had heard of to date, a novel cross-Atlantic challenge co-sponsored by the UK and US governments, and a hairy legal technology challenge bearing down upon societies everywhere: what happens when software interprets the law?
For instance, he suggested, consider the increasing use of Oracle software around legislation. “As statutes are interpreted by software, what’s introduced by the code? What about quality testing?”
As this becomes a data problem, “you need information to contextualize it,” said Sheridan. “If you’re thinking about legislation as code, and as data, it raises huge questions for the rule of law.”
Open data as a platform
In the video below, John Sheridan talks about the benefits of opening up government data using application programming interfaces:
Sheridan has been one of the world’s foremost proponents of publishing legislative data through APIs, an approach that has come under criticism by open government data advocates after the government shutdown in the United States. (In 2014, forward-thinking governments publishing open data might consider provide basic visualization tools to site visitors, API access for third-party developers and internal users, and bulk data downloads.) One key difference between the approach of his team and other government entities might be that the National Archives are “dogfooding,” or consuming the same data through the same interface that they expect third-parties to use, as Sheridan wrote last March:
“We developed the API and then built the legislation.gov.uk website on top of it. The API isn’t a bolt-on or additional feature, it is the beating heart of the service. Thanks to this approach it is very easy to access legislation data – just add /data.xml or /data.rdf to any web page containing legislation, or /data.feed, to any list or search results. One benefit of this approach is that the website, in a way, also documents the API for developers, helping them understand this complex data.”
Perhaps because of that perspective, Sheridan, was as supportive of an APIs when we talked this September as he had been in 2012:
The legislation.gov.uk API has changed everything for us. It powers our website. It has enabled us to move to an open data business model, securing the editorial effort we need from the private sector for this important source of public data. It allows us to deliver information and services across channels and platforms through third party applications. We are developing other tools that use the API, using Linked Data – from recording the provenance of new legislation as it is converted from one format to another, to a suite of web based editorial tools for legislation, including a natural language processing capability that automatically identifies the legislative effects. Everything we do is underpinned by the API and Linked Data. With the foundations in place, the possibilities of what can be done with legislation data are now almost limitless.
Sheridan noted to me that the United Kingdom’s legislative open government data efforts are now acting as a platform for large commercial legal publishers and new entrants, like mobile legislative app, iLegal.
 The iLegal app content is derived from the legislation.gov.uk API and offers handy features, like offline access to all items of legislation. iLegal currently costs £49.99/$74.99 annually or £149.99/$219.99 for a lifetime subscription, which might seem steep but is a fraction of the cost of of Halsbury’s Statutes, currently listed at £9,360.00 from Lexis-Nexis.
The iLegal app content is derived from the legislation.gov.uk API and offers handy features, like offline access to all items of legislation. iLegal currently costs £49.99/$74.99 annually or £149.99/$219.99 for a lifetime subscription, which might seem steep but is a fraction of the cost of of Halsbury’s Statutes, currently listed at £9,360.00 from Lexis-Nexis.
This approach to publishing the laws of the land online, in structured form under an open license, is an instantiation of the vision for Law.gov that citizen archivist Carl Malamud has been advocating for in the United States. 2013 saw some progress in that vein when the U.S. House of Representatives publishes U.S. Code as open government data.)
What’s notable about the United Kingdom’s example, however, is that less then a decade ago, none of this could have been possible. Why? As ScraperWiki founder Francis Irving explained, the UK’s database of laws was proprietary data until December 2006. Now, however, the law of the land is released back to the people as it is updated, a living code available in digital form to any member of the public that wishes to read or reuse it.
The United Kingdom, however, has moved beyond simply publishing legislation as open data: they’re actively soliciting civic participation in its maintenance and improvement. For the last year, the National Archives has been guiding the world’s leading commercial open data curation project.
“We are using open data as business model for fulfilling public services,” said Sheridan, in our interview. “We train people to do editorial work. They are paid to improve data. The outputs are public.”
In other words, the open government data always remains free to the people through legislation.gov.uk but any academic, nonprofit or commercial entity can act to add value to it and sell access to the resulting applications, analyses or interfaces.
As far as Sheridan could recall, this was the only such example in the government of the United Kingdom where such a feedback loop exist. The closest parallels in the United States is the U.S. Agency for International Development crowdsourcing geocoding 117,000 loan records with the help of online volunteers [Case Study] or the citizen archivist program of the U.S. National Archives.
Since the start of the UK project, they have doubled the number of people working on their open data, Sheridan told me. “The bottleneck is training,” he said. “We have almost unlimited editorial expertise available through our website. We define the process and rules, and then let anyone contribute. For example, we’re now working on revising legislation, identifying changes, researching it — when it comes in, what it affects — and then working with editor. Previous to this effort, government hasn’t been able to revise secondary legislation.”
Sheridan said that the next step is feedback for other editorial values.
“We’re looking for more experts,” he said. “They’re generally paid for by someone. It’s very close to open source software model. They must be able to demonstrate competence. There’s a 45-minute test, which we’re now given to thousands of people.”
If this continues to work, distributed online collaboration is a “brilliant way to help improve the quality of law,” said Sheridan.
“It’s a way to get the work done — and the work is really hard. You have to invest time and energy, and you must protect the reputation of the Archive. This is somewhat radical for the nation’s statute book. We have redesigned the process so people can work with us. It’s not a wiki, but participation is open. It’s peer production.”
A trans-Atlantic challenge to map legislative data

In September, Sheridan also told me about an unusual challenge that has just gone live at Challenge.gov, the United States’ flagship prizes and competitions platform: a contest to assess the compatibility of Akoma Ntoso with U.S. Congress and U.K. Parliament markup languages.
Second Library of Congress Legislative Data Challenge Launched, with US and UK Bills. See: http://t.co/t5ZrN3k0sp cc @digiphile
— legislation.gov.uk (@legislation) September 20, 2013
The U.K. National Archives and U.S. Library of Congress have asked for help mapping elements from bills to the most recent Akoma Ntoso schema. (Akoma Ntoso is an emerging global standard for machine-readable data describing parliamentary, legislative and judiciary documents.) The best algorithm that maps U.S. bill XML or UK bill XML to Akoma Ntoso XML, including necessary data files and supporting documentation, will win $10,000.
If you have both skills and interest, get cracking: the challenge closes on December 31, 2013.
