
This past week, Facebook launched a new political ad transparency website. Facebook believes that “shining a light on ads” will increase transparency, which in turn “will lead to increased accountability & responsibility over time – not just for Facebook but advertisers as well.“
I think they’re right — which should be no surprise given my focus on advocating for more political transparency in Washington over the two years I spent at the Sunlight Foundation — but reviewing reports of unlabeled political ads is going to be hard.
Overall, this site is a welcome step towards more transparency, but misses the mark. The site only “exceeds expectations” if you think a search interface that exposes no underlying data is sufficient to inform the public and regulators.
In my initial assessment, I concur with journalists who found Facebook’s new political ad system is missing a lot, as ProPublica reported. (Please install ProPublica’s political ad collector so they can inform the public about how well Facebook’s tool actually works.)
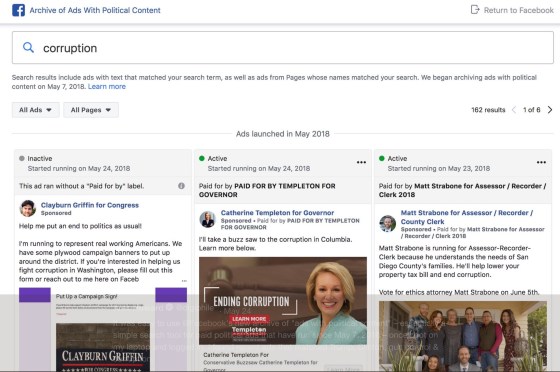
It was easy to use @Facebook‘s new archive of “ads with political content” – essentially a simple search tool for paid political ads that have run since May 7, 2018 – once I got on my laptop and logged in. I found recent ads that matched Trump, Clinton, gun control & corruption. pic.twitter.com/Fhx0lrMzBE
— Alex Howard (@digiphile) May 24, 2018
https://platform.twitter.com/widgets.js
On the one hand, it was easy to use Facebook’s new archive of “ads with political content” – essentially a simple search tool for paid political ads that have run since May 7, 2018 – at least once I got on my laptop and logged into Facebook. I found recent ads that matched Trump, Clinton, gun control and corruption.
If you click on “see ad performance,” you can learn more about each ad.
If you click “see ad performance,” you see the ad content, who paid, when it was active, how many impressions it received, total spent, & breakdown of audience by age, gender & location.
But clicking “view all ads” brings you to aggregate search results, NOT the page or a profile pic.twitter.com/8XtzmWqdYy
— Alex Howard (@digiphile) May 24, 2018
If you click on the username, you arrive at the Page behind the ads. Unfortunately, there’s no tab for political ads or link to this archive. It’s hard to see how folks will find them, without it.
If you click on the username – in this case, Donald Trump, @realDonaldTrump‘s campaign account on @Facebook – you arrive at the Page behind the ads. Unfortunately, there’s no tab for political ads or link to this archive. It’s hard to see how folks will find them, without it. pic.twitter.com/EASlccVAhF
— Alex Howard (@digiphile) May 24, 2018
As I noted on Twitter, however, there’s one more critical wrinkle: you can’t get to the page unless you’re logged into Facebook!
This would be hilariously ironic, if it weren’t for the context of Russian interference and how Facebook handled it. Self-regulation is not enough.
As sociology professor Zeynep Tufecki noted, no one — whether member of the public, the press, watchdog, academic, regulator or legislator – should have to agree to Facebook’s Terms of Service and become a user to access political data.
😱 You shouldn’t have to agree to Facebook TOS in order to access information about political reports. In fact, that is a core problem. I’ve seen examples where schools put *emergency* information on Facebook and people have to agree to FB TOS to learn whether children are safe. https://t.co/6kmsOXgYgu
— zeynep tufekci (@zeynep) May 24, 2018
To Facebook’s credit, the director of product at Facebook, Rob Leathern, responded publicly to Tufecki on Twittter, stating that this page is a first step:
“More ways are coming to make the ads with political content and information more accessible to people. One of those is an API, another is exploring opening the archive to people not on Facebook. We started with the Facebook community to see how they use the tool and gain feedback from third parties, including our newly-formed Election Commission. We’ll continue to update on our progress.”
If Facebook started with open data with no log-in, they could have gotten feedback from third parties like the Center for Responsive Politics or the public. No one should have to be part of Facebook’s “community” to understand who is buying electioneering on the platform, for whom, and what’s being shown.
As I commented to Leathern, if Facebook is only “exploring” making this archive open to people not on Facebook, then it is not implementing the Honest Ads Act, as its staff has claimed to Congress and the public. I asked Facebook to post a public ad file as bulk open data on the open Web.
Leathern told me that “we have prioritized getting the archive in the hands of people to use (as of today) + will follow up soon with an archive API. Thank you for the feedback, we are definitely listening.”
That’s good news, but not good enough.
Real transparency at Facebook will look like a public file of all paid political ads that are disclosed on a public website with bulk open data downloads and an API, none of which require the public to log into the site.
The good news is that I think Facebook understands this page as a start, not an end. In a post that closes matches what he told me, Leathern wrote that they’re “working closely” with a new “Election Commission” to launch an API for the archives.
It’s good news, but no deadline cited.
It’s hard for me not to be happy that Facebook is finally explicitly embracing political ad transparency in words and (some) deeds, including public soul searching about what constitutes a political ad and a policy.
That’s progress.
It’s just long overdue. Ultimately, elected representatives should be the ones to enact standards for transparency for political ads online after debate, not tech company executives.
Until Congress and other legislatures around the world empower regulators like Federal Election Commission by updating electioneering rules and enacting standards for disclaimers and disclosures, however, I’m glad to see positive actions.
I hope Facebook, its founder and its staff deliver on its most recent promises and their public obligations. Given past, current or predictable interference, opacity is unpatriotic.

